- Batch Data Vs Streaming Data …
- Indefinite flow of data …
- #Process_Pattern_1 : Process data as and when it is available.
Recently my friend has asked me, “Dude, it’s been quite some time that you have been working on Big Data and related software stacks. I have a simple problem and could you please educate me on these jargons and provide a suitable solution ? “
The inherent repulsive behaviour in me have put me in a defensive mode but I somehow mustered enough courage to hear the problem statement out and it goes like this :-
"Let's assume that you have a stream of data flowing in and I want to put the data into different buckets by aligning with the following rules :-
1. The records in a given bucket shouldn't be duplicates
2. All the incoming data should be emitted out i.e the collection of data in different buckets will be the same as incoming data.
Once, the data is arranged in different buckets, we should be able to call a Sink. Let's assume this as an HTTP API Service / HDFS output location.
Whenever I am encountered with a problem, I will try to picturise the statement in my mind (I assume our brain has some ‘magical’ power to process and give out results when we lift problem statements into diagrams with box and connectors :) ) and that goes like this :-
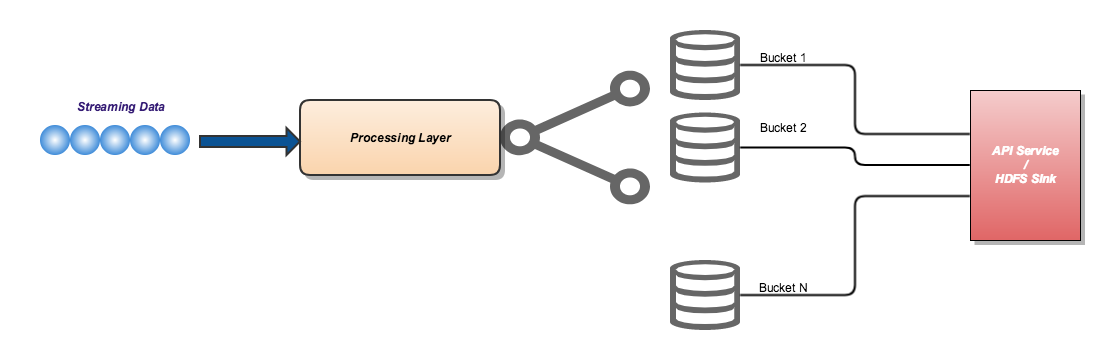
Ok, we are successful in plotting the problem statements using box and connectors. But, I already find myself bombarded with lot of questions which I am not certain about.
- What is a streaming data ?
- What is the best mechanism to ingest it.
- Even if I find a mechanism to ingest the data how much of the incoming data will can be processed at a time ?
- What all things can be done with the streaming dataset and methods available for sink ?
We will try to answer each of these questions at different points in the journey.
As we all do, my immediate reflex was to google on these jargons and without much hassle I was able to come up with the following conclusions.
Batch Data Vs Streaming Data …
In real world data is generated majorly in two ways, end result of a statistical analysis or by the end result of an event. Lets say, if I am periodically checking the account balances of customers in a bank or memory usage in a computer and records it as a dataset then it can be fairly be categorised as dataset derived out of statistical analysis. There is another class of dataset generated out of instances like data generated by sensors, security systems, medical devices based on events happening at their habitat. We couldn’t simply predict the occurrence interval of those data. For instance, lets treat the webserver logs as a dataset and the data will be continuously generated whenever someone accesses any of the websites hosted on that server. This continuous flow of events can be called as streaming dataset. In a typical Big Data Environment, the need for performing real-time stream processing is rapidly increasing and below is some witty but striking example to reason the statement.
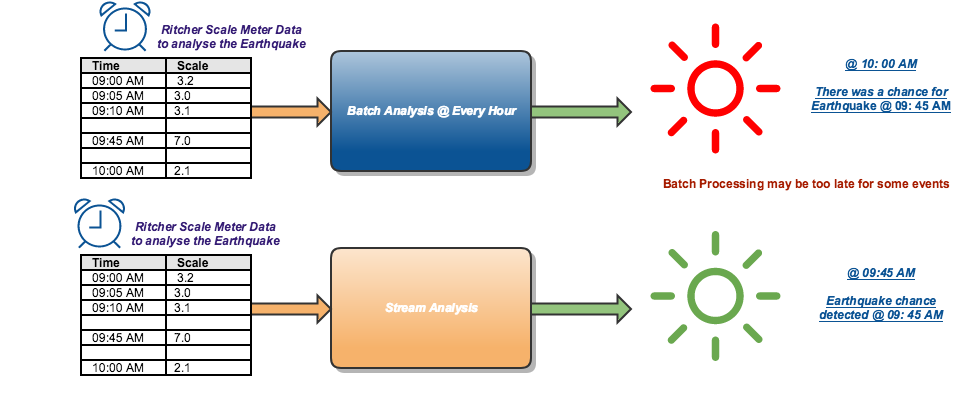
Indefinite flow of data …
Now that we know the difference between the Batch Data and Streaming data processing, the very first concern that would come to our mind is its behaviour - the indefinite flow of incoming data. We should have a mechanism to make sure that all the incoming data is processed as and when it is available. In layman terms, I can think of couple of ways to handle this scenario
- Have a processing layer capable of processing the data as and when it is available. - #Process_Pattern_1
- Have a queueing system in place to hold the incoming data and let the processing layer source the data from there and process. #Process_Pattern_2
On further research, I narrowed down my options for the Processing Layer. We can either use Spark Streaming / Storm as a processing layer and and Kafka / Flume as queuing system to control the flow of incoming data before it is served for processing.

But, in this post we will be concentrating only on the Spark Streaming + Kafka Integration to implement the solution to the problem we had started with.
#Process_Pattern_1 : Process data as and when it is available.
Before coming into a solution, we will try to get a basic understanding about the Processing Layer (Spark Streaming) using a simple network word count application. Let’s assume that we have a netcat server as a source for streaming dataset and our aim is to compute the word count on the incoming data. In the case of batch mode word count, Simple Word Count using Spark, we were reading in the source dataset, doing the RDD transformations and computes the word count on the whole dataset and finally the results were written on to the disk. In that case the actual computation was done on the whole dataset. But, when it comes to the real time streaming, we do not know what can be the size of the dataset and when should the computation on that defined dataset be emitted out. This is where the relevance of a ‘streaming-batch’(think about separation of concerns :) ) comes into picture.
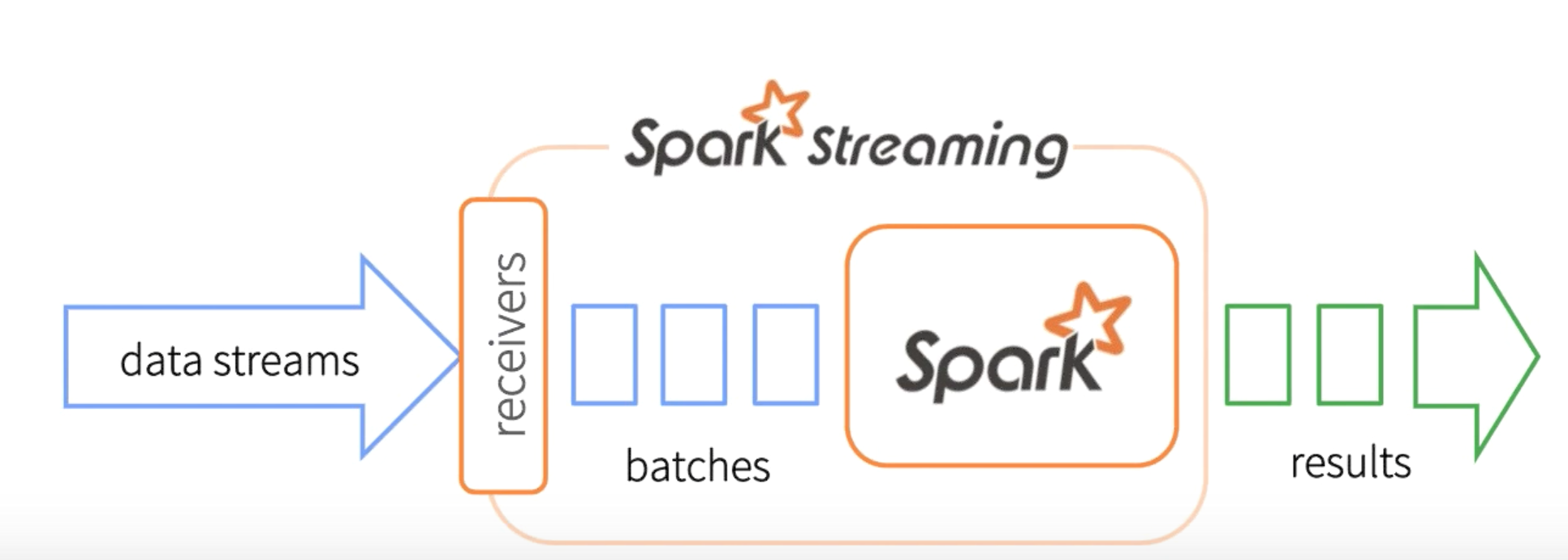
Yes, you guessed it right. In a streaming context it is not the amount of data that defines a batch but rather it’s the time duration that defines it. If you split the timeline into intervals of say 1s, 2s or 3s etc then we can very well define a batch as the totality of data that came over that period of time. But the Spark Streaming optimizes the streaming batches by introducing one more concept called DStreams. Spark Streaming divides the data stream into batches of X seconds called Dstreams(Discretized Streams), which internally is a sequence of RDDs, one for each batch interval. Each RDD contains the records received during the batch interval.
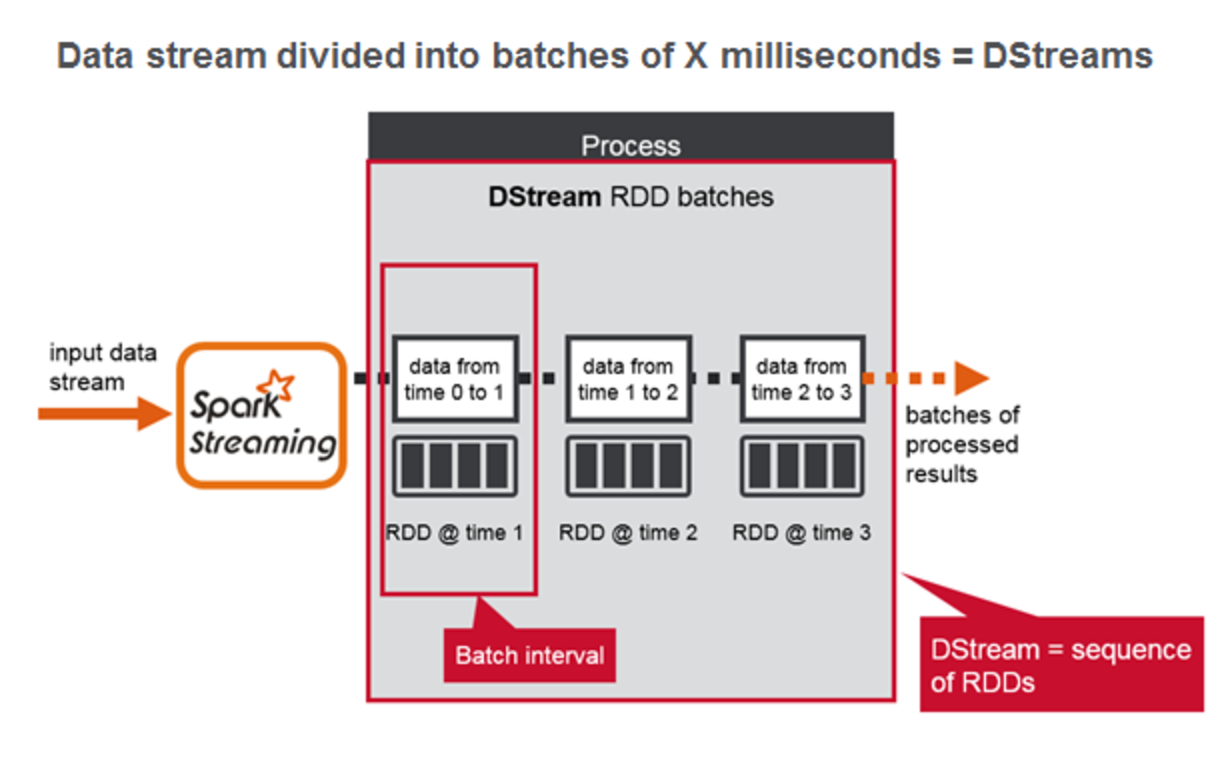
Before going further into any more discussion, we will switch our context back to the WordCount Program (Yep, Bottom Down approach). Suppose we have a streaming data source(netcat, for the time being) and we want to perform the word count on the streaming dataset. The implementation is given below for reference.
// Create the context with a 1 second batch size
val sparkConf = new SparkConf().setMaster(args(0)).setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))
// Create a socket stream(ReceiverInputDStream) on target ip:port
val lines = ssc.socketTextStream(args(1), args(2).toInt, StorageLevel.MEMORY_ONLY)
// Split words by space to form DStream[String]
val words = lines.flatMap(_.split(" "))
// count the words to form DStream[(String, Int)]
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
// print the word count in the batch
wordCounts.print()
ssc.start()
ssc.awaitTermination()
Internally, it works as follows. Spark Streaming receives live input data streams and divides the data into batches, then the sequence of RDDS(DStreams) will then be processed by the Spark engine to generate the final stream of results. There are two types of operations on DStreams i.e transformations and output operations. Every Spark Streaming application processes the DStream RDDs using Spark transformations which create new RDDs. Any operation applied on a DStream translates to operations on the underlying RDDs, which in turn, applies the transformation to the elements of the RDD. Output operations, like saving the HDFS or calling an external API will produce output in batches.
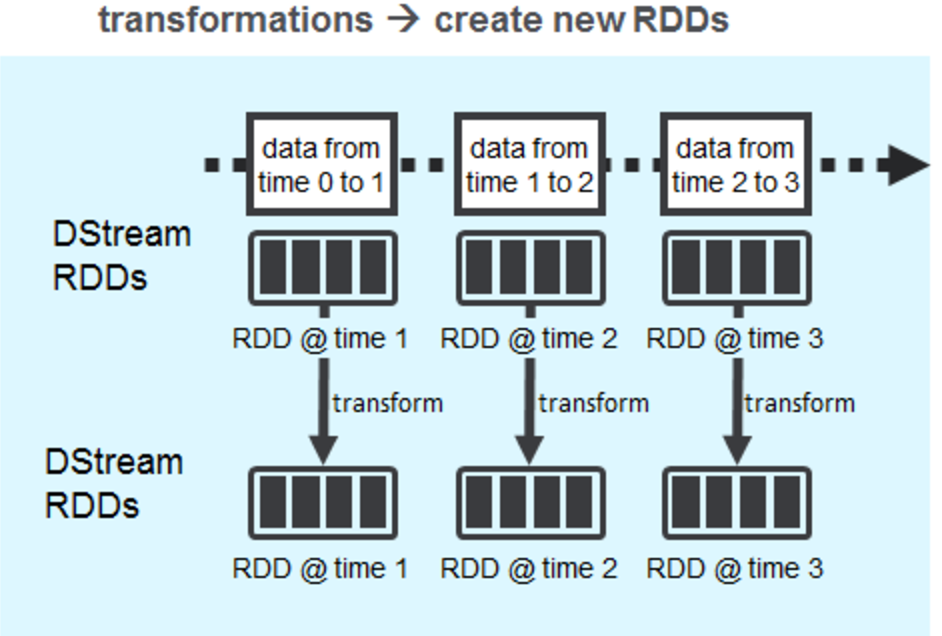
Yes, the opportunist in you have guessed it right, once we have a sequence of RDDS - you are empowered and transcended to a a world where you are free to do anything which you can perform on an RDD - be it MLlib, Graph and you name it - Awesomeness!
Something is worrying You!
Yes, from the top of my head, I could sense a lot of questions cooking up.
- Will I be able to process all the data which streams in ?
- what all things have been considered for the fault-tolerance while processing this fast paced data ingest
- Who will be responsible for receiving the data etc.
Ok, since everything ultimately boiling down to RDD processing, we very well know that the processing will ultimately happen in Spark Driver Program and Executors.
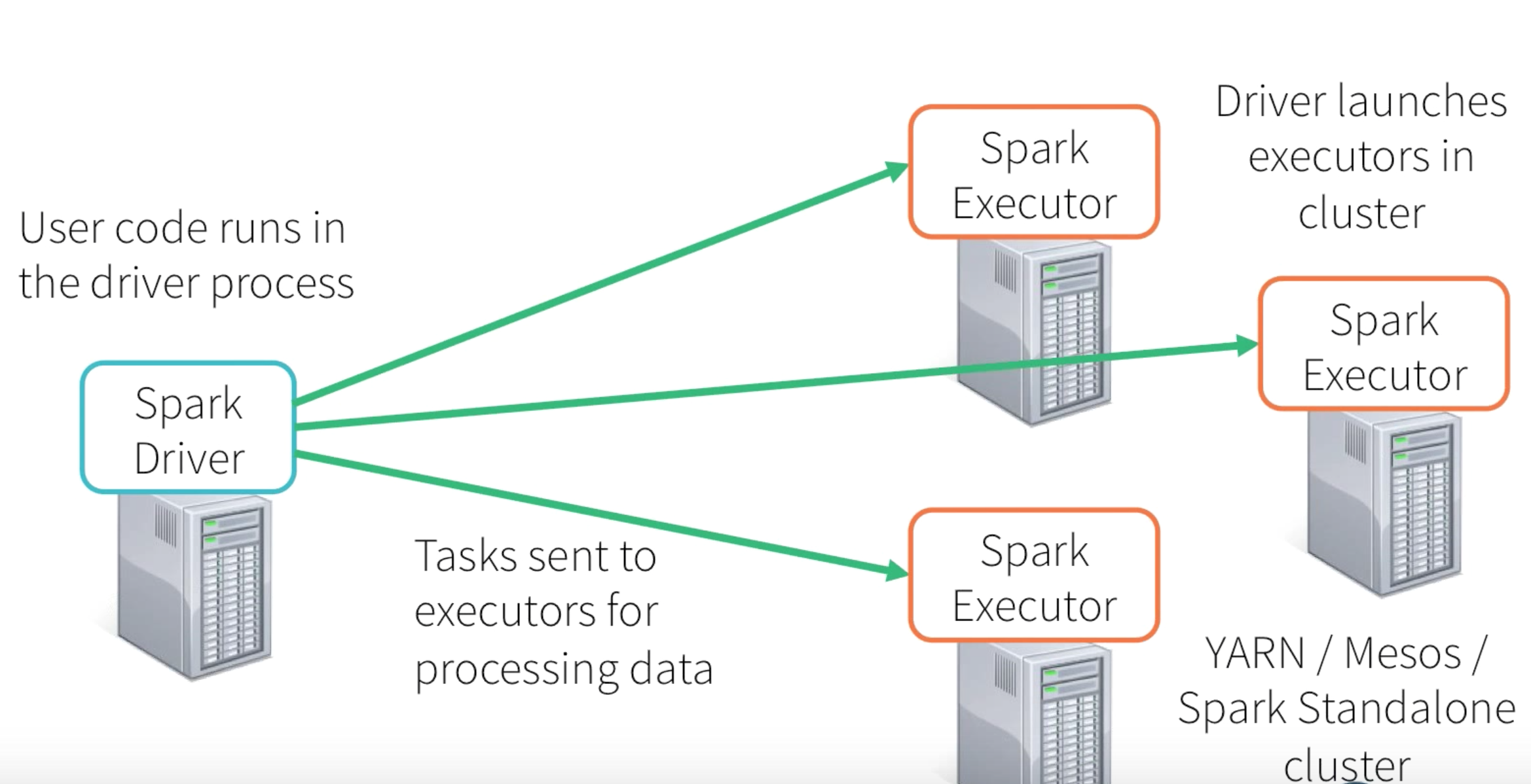
Let’s try to solve the questions in the chronological order of relevance and see whether we can come up with some answers. In that case the very first question would be how will be responsible for receiving the data.
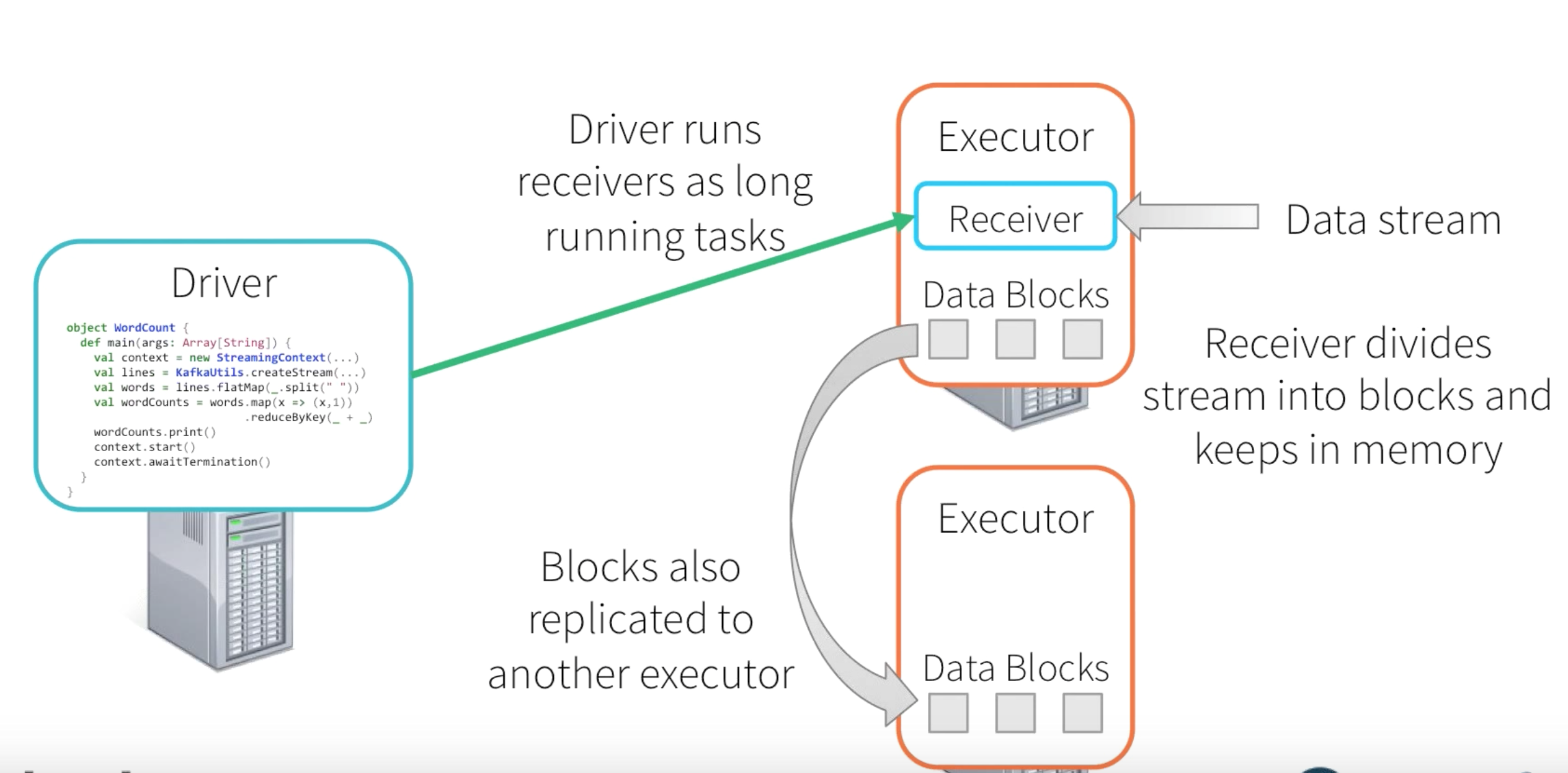
Depending upon the type of input streaming data source, the corresponding DStream is associated with a Receiver object which receives the data from a source and stores it in Spark’s memory for processing. Spark Streaming provides two categories of built-in streaming sources.
- Basic sources: Sources directly available in the StreamingContext API. Examples: file systems, and socket connections.
- Advanced sources: Sources like Kafka, Flume, Kinesis, etc. are available through extra utility classes.
In the current Context(Network Word Count), we are using the ReceiverInputDStream for the Socket Stream Source. The Receivers are long running process in one of the Executors and its life span will be as long as the driver program is alive. The Receiver receives data from socket connection and separates them into blocks. This generated block of data will be replicated among different executor memory. On every batch interval the Driver will launch tasks to process the blocks of data and the subsequent results will be sinked to the destination location.
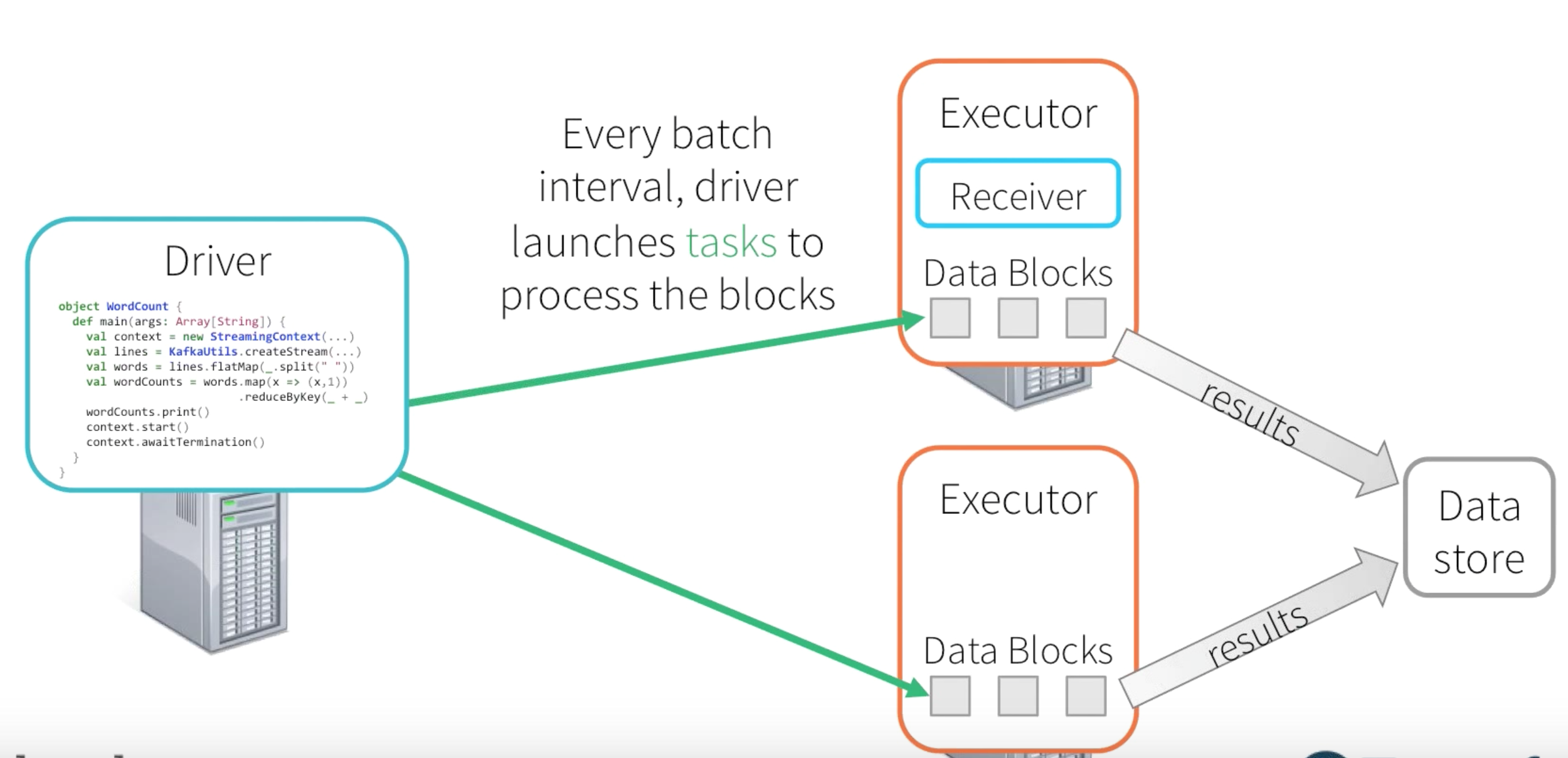
Okay, now that we have the answer for the question on who will be responsible from receiving the streaming data, the next intriguing question would be on the fault-tolerance. We know that everything is now boiled down to Spark native habitat the possible faulty prone scenarios that can occur would be : -
-
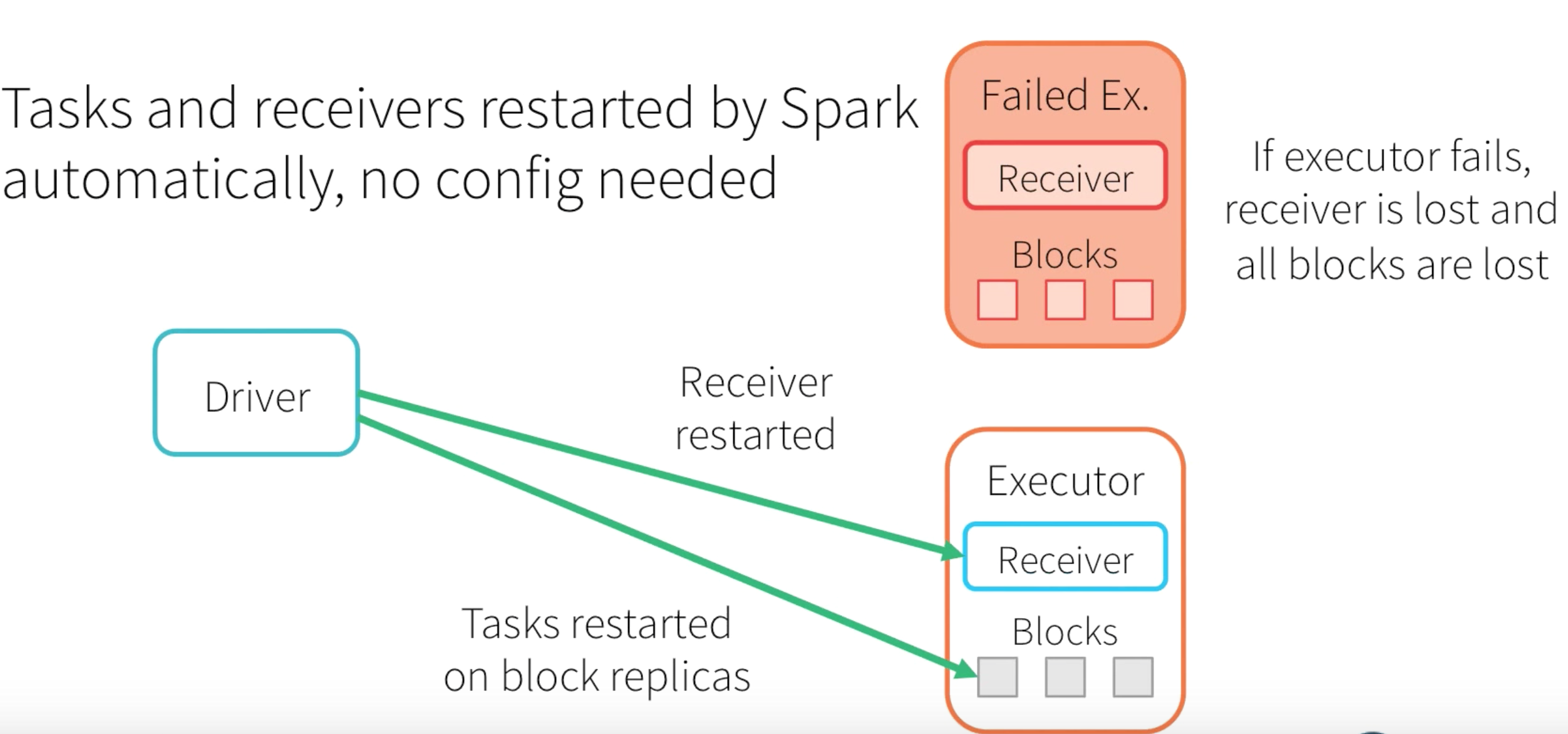
What if the Executor Fails : -
If the Executor is failed then the Receiver and the stored memory blocks will be lost and then the Driver will trigger a new receiver and the tasks will be resumed using the replicated memory blocks.
-
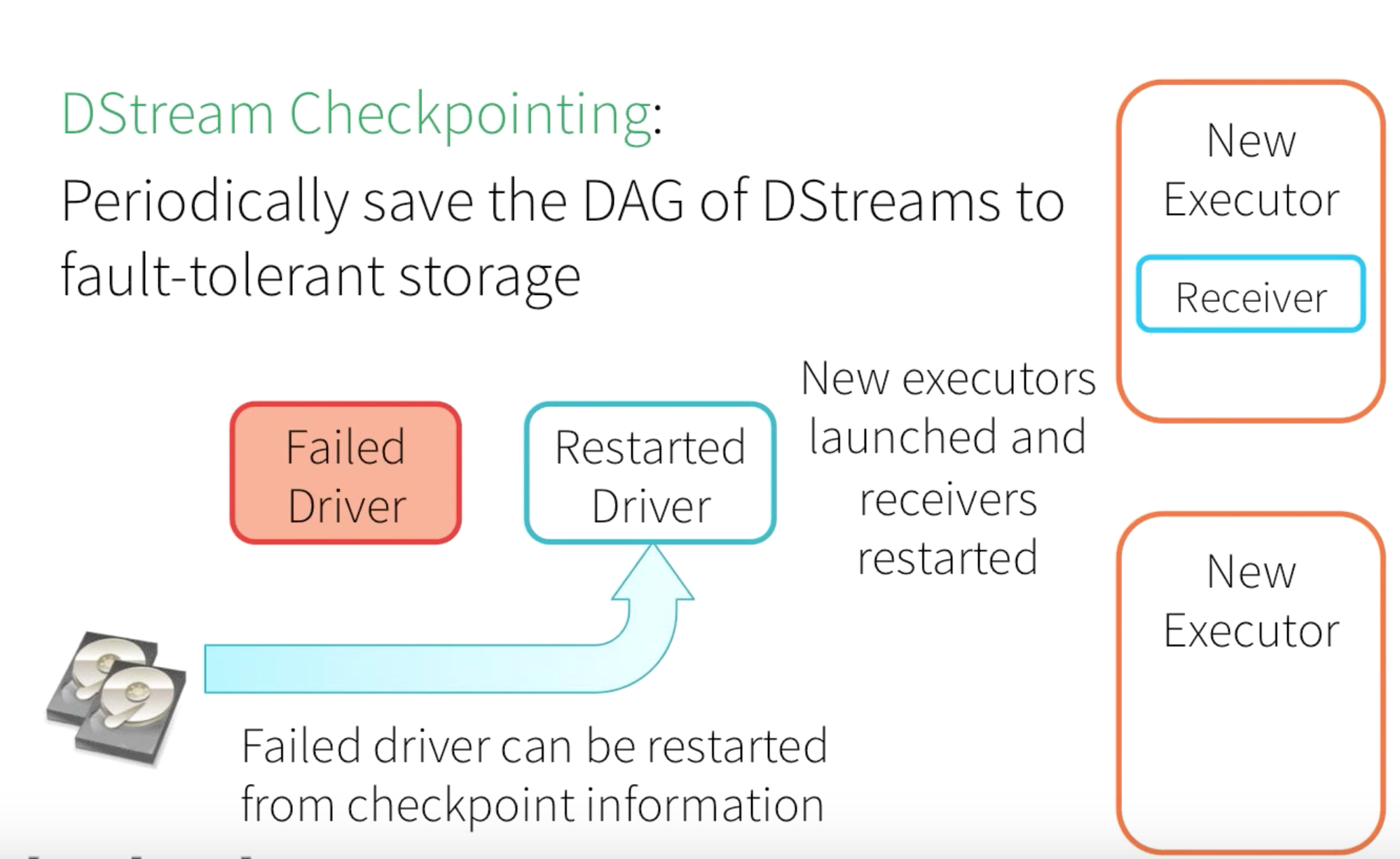
What if the Driver Program Fails : -
When the Driver Program is failed, then the corresponding Executors as well as the computations, and all the stored memory blocks will be lost. In order to recover from that, Spark provides a feature called DStream Checkpointing. This will enable a periodic storage of DAG of DStreams to fault tolerant storage(HDFS). So when the Driver, Receiver and Executors are restarted, the Active Driver program can make use of this persisted Checkpoint state to resume the processing.
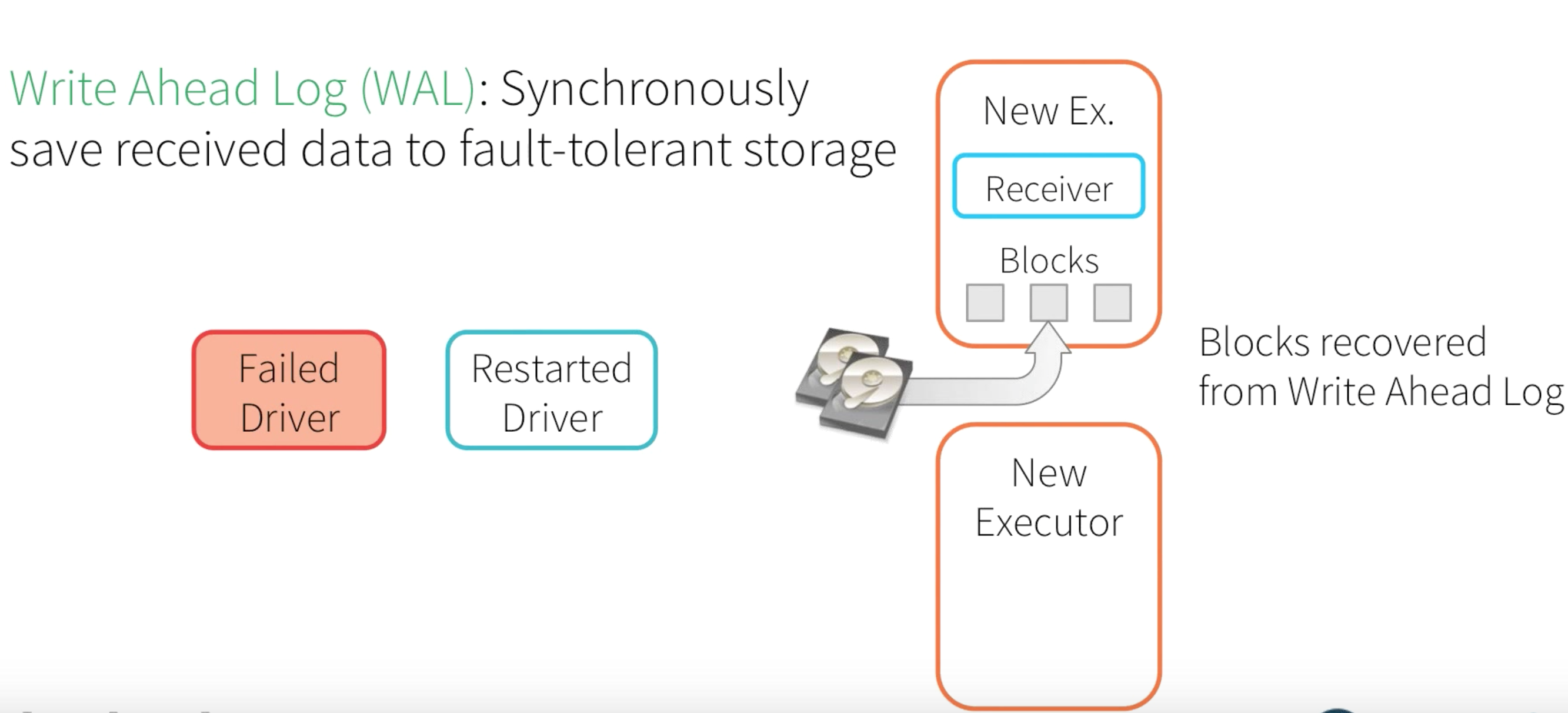
Even if we are able to restart the Checkpoint state and start processing from the previous state with the new Active Executor, Driver program, and Receiver - we need to have a mechanism to recover the memory blocks at that state. In order to achieve this, Spark comes with a feature called Write Ahead Log (WAL) - This will synchronously saves memory blocks into fault-tolerant storage.
To enable the whole fault-tolerance, we should perform the following changes to our Network WordCount Program : -
- Enable Checkpointing
- Enable WAL in SparkConf
- Disable in-memory Replication
- Receiver should be reliable : Acknowledge Source only after data is saved to WAL. Untracked data will be replayed from source.
If you apply the above fault-tolerance changes then the whole NetworkWordCount program will look something like this : -
def main(args: Array[String]) {
if (args.length < 3) {
System.err.println("Usage: NetworkWordCount <master> <hostname> <port> <duration> <checkpoint directory>")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
val ssc = StreamingContext.getOrCreate(args(4), () => createContext(args))
ssc.start()
ssc.awaitTermination()
}
def createContext(args: Array[String]) = {
// Create the context with a 1 second batch size
val sparkConf = new SparkConf().setMaster(args(0)).setAppName("NetworkWordCount")
sparkConf.set("spark.streaming.receiver.writeAheadLog.enable", "true")
val ssc = new StreamingContext(sparkConf, Seconds(args(3).toInt))
// Create a socket stream(ReceiverInputDStream) on target ip:port
val lines = ssc.socketTextStream(args(1), args(2).toInt, StorageLevel.MEMORY_AND_DISK_SER)
// Split words by space to form DStream[String]
val words = lines.flatMap(_.split(" "))
// count the words to form DStream[(String, Int)]
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.checkpoint(args(4))
ssc
}
Have you noticed something fishy in the existing implementation - Hmm, A reliable friend - Yes, a reliable source who can acknowledge our hope, well-being and happiness :).
We will talk about that in the sequel… To Be Continued! :)