Please note that this is a continuation from Spark Architecture : Part 1 - Making sure that the basement is right!
Baby Step 1 : Prepare your executable
Now that we have the cluster (with HDFS Layer, Node Manger and Resource Manager) in place we will name this state as ‘Dot1’. Keeping this aside, now we will switch our context back to the WordCount Program we have already written and tested WordCount - Spark Our aim is to run this WordCount Program in Spark Cluster and see how it interacts with different components and dissect each components to see what exactly is happening under the hood to define rest of the components in the Architecture.
// RDD 1
val inputRDD = sc.textFile(inputPath)
// RDD2
val wordsRDD = inputRDD.flatMap(_.split("\\s+")) // split words
// RDD 3
val tuplesRDD = wordsRDD.map(w => (w, 1))
// RDD 4
val reducedRDD = tuplesRDD.reduceByKey(_ + _)
// Action
reducedRDD.saveAsTextFile(outputPath)
So the core of the WordCount Program is shown above and we are ready with the executable. In the cluster, we have already identified a physical machine as the Edge Node(Assume that we have already installed the Spark Cluster and all the Spark Binaries are available in the Edge Node). When we submit the Job, the execution flows through the following steps.
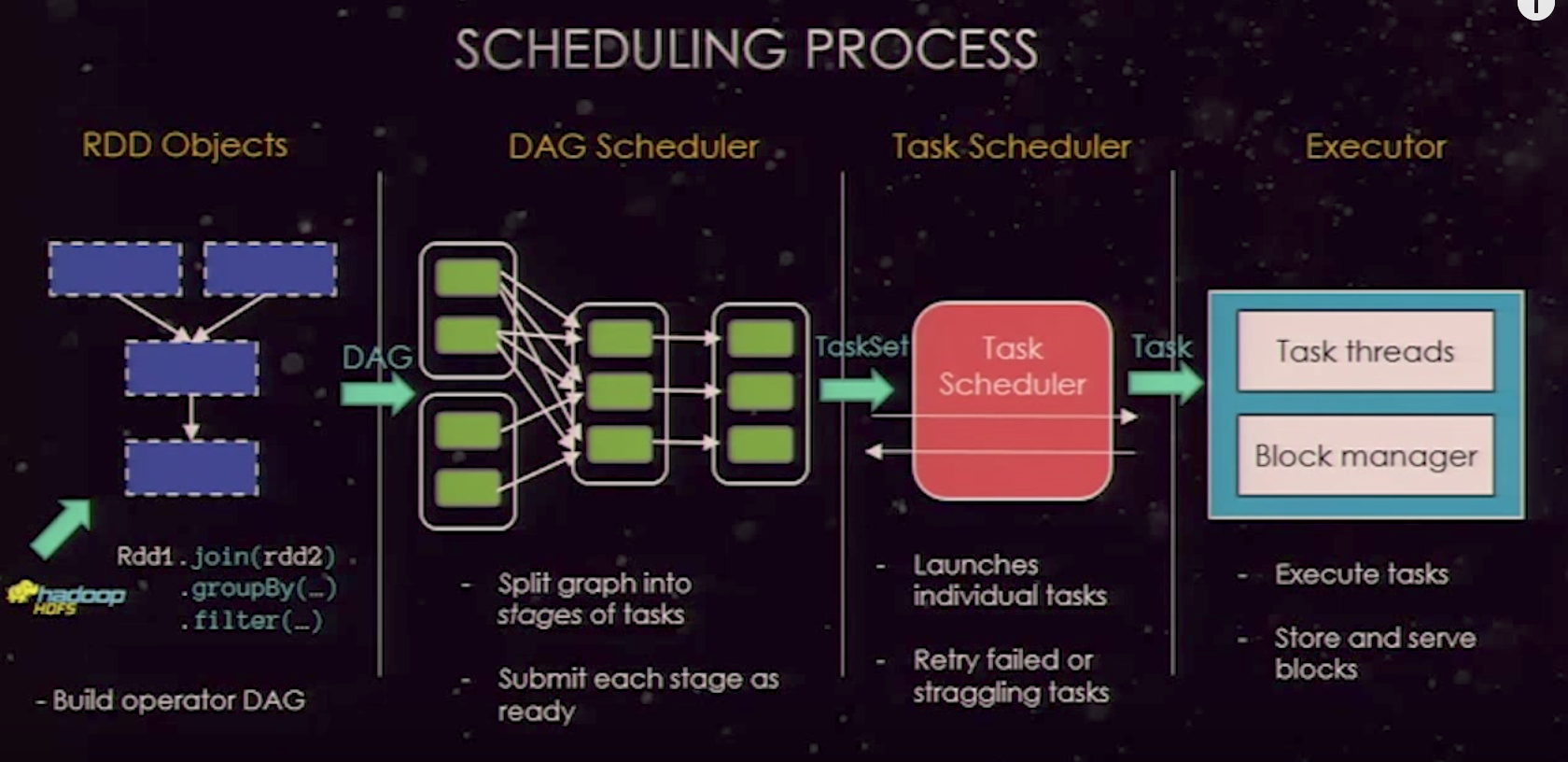
- Spark Will identify what is the List of RDDs in the program and the lineage between them. When any action(Actions & Transformation) is called on the RDD, spark creates the DAG(Directed Ascylic Graph) and sends it to the DAG Scheduler.
-
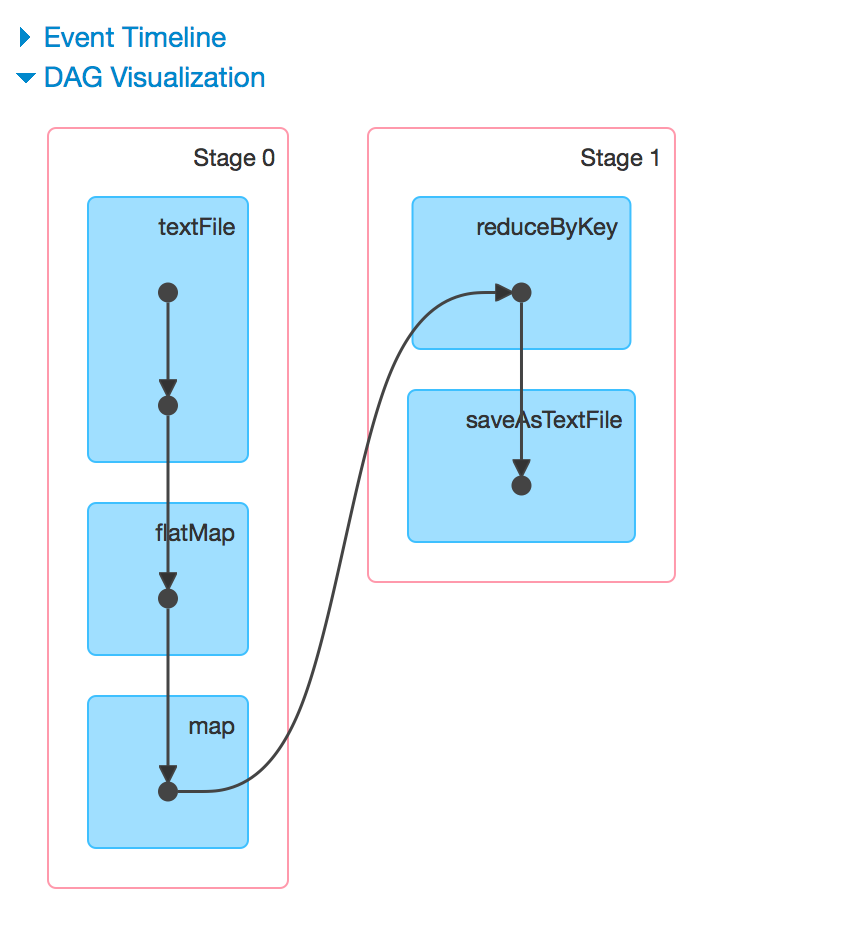
The DAG Scheduler splits the operations into different stages. As we already discussed there are mainly two types of operations that result in RDD - i.e Transformations and action among this there can be two types of Transformations one is narrow transformation and the other one is wide transformation(involves shuffling - i.e network transfer). The wide transformation determines the stage boundaries(i.e it is a trigger for next stage; Eg: reduceByKey, groupBy etc). So our WordCount program, RDD4 defines the boundary and all the operations in RDD1, RDD2 and RDD3 can go in single stage and the operations can be coupled together and parallelised. RDD4, RDD5 groups together to form the Stage 2.
-
Once the DAG is generated, each stages will be send as an input to the Task Scheduler to generate the physical execution plan. The number of physical tasks spawned depends on the number of partitions generated out of the file (Based on Block size). For instance, in our case say if we are processing 1.5 GB data then the number of tasks spawned will be 1.5 GB / 128 MB = 12. Now the question is how these tasks are shared to get the work done. That is where the Worker Node comes into the picture. Ok, now that I have 12 tasks to process and assume that spark(by default) spawned two Executors to to get the work done. Let’s assume that the 2 executors spawned are having the configuration of 512 MB (Container Memory) and 1 V-Core and we have 12 Tasks to complete. It is very obvious that the all of the 12 tasks can be processed at once because the core will only function in a time sharing manner and at most 2 tasks can be executed in parallel. So task1 will be allotted to the Executor of the node 1 (Depends on the data locality) and the task 2 will be allotted to the next. Depending up on whoever completes the task first will get the subsequent task allocated and once all the 12 Tasks are done in this fashion, the Stage 1 will be completed.
The Stage 2 (Starts with the shuffled dataset) will always have the same number of tasks as that of the stage 1(unless and otherwise if you repartition the RDD)
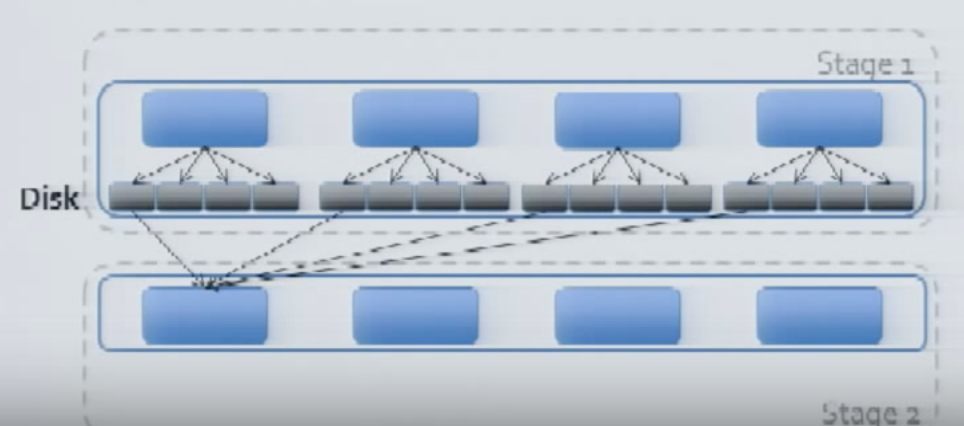
The tasks of the Stage 2 will also get executed based on the Executor/Core availability and the final data will be written on to the target file.
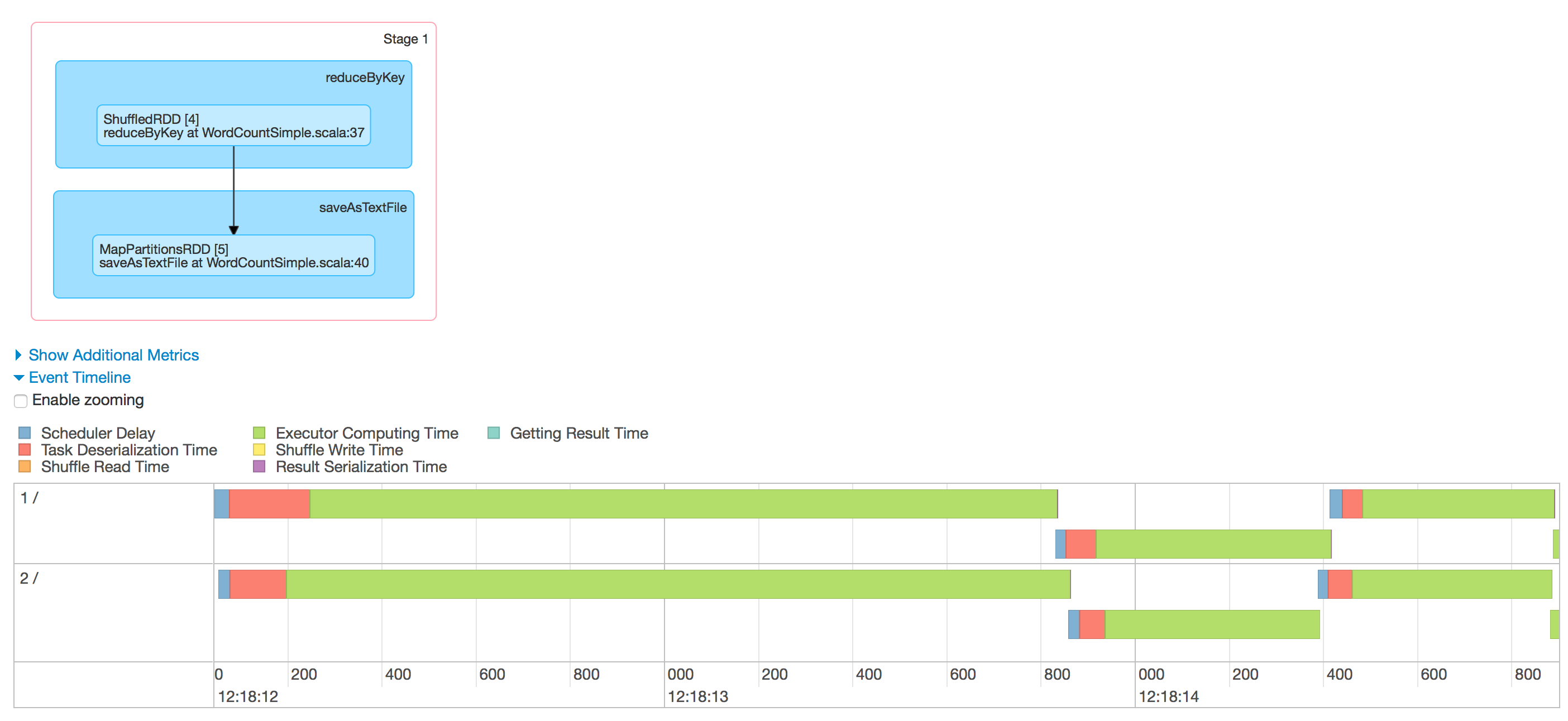
One interesting thing to notice over here is that the Mapper and Reducer Phases ran on the Same Node and they are re-using the Executor JVM for the processing and this is one of the main reason why Spark is so Powerful (Yes, the Caching Mechanism to store the data in RAM is also there). There are more things coming up on the Memory Management and Executor Memory Turning on Part 3 - One More Baby Step : Executor Memory Management and Tuning