- The basics (Quick glance through what we already know)
- Connecting the Dots
- Connecting the Dots - The Capacity of our Cluster!
When I wanted to learn about Spark and its Architecture, to get it from horses mouth, I went directly to the Apache Spark homepage Spark Architecture. Not surprisingly, I was presented with a neat Architecture diagram and a collection of jargons to start with - Cluster manager, Driver Program, Spark Context, Worker node, Executor, Task, Job, Stage.
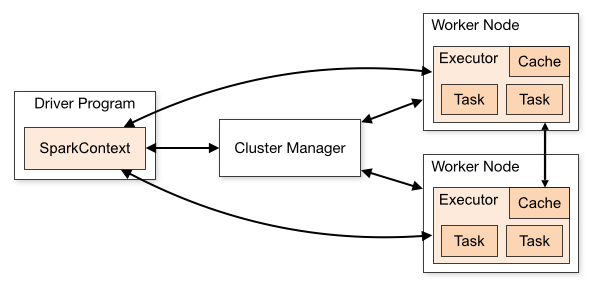
Since I have been working with Big Data Technologies for quite some time, I was able to map the things on a high level. Not recently, I started imbibing a pattern of learning in which I mark something as learned if and only if I am successful in making another person understand that concept in the most simple terms. So sticking on to that thumb rule and to force the zen pattern, I am trying to to explain the Architecture from a different(more practical) point of view(I presume you have basic understanding of Hadoop and MapReduce).
The basics (Quick glance through what we already know)
We all know that the Spark Architecture sits on top of the Hadoop Platform. So, the simple layman question - What is a Hadoop cluster and why do we need it ?
As per Wiki - Apache Hadoop is an open-source software framework used for distributed storage and processing of dataset of big data using the MapReduce programming model.
To understand the need and evolution of Hadoop-MapReduce, I suggest you to go through the below write up :-
Evolution of Hadoop and MapReduce
P.S : - More to Come on this introduction part.
Connecting the Dots
Ok, Let’s try to see the whole architecture from a different perspective. We all know that the Hadoop cluster is “made” using the commodity Hardwares and let’s assume that we have 5 Physical machines each of them is having a basic configuration (16GB RAM, 1 TB HDD, and 8 Core Processors).

Ta-da, we have got the physical machines in place and we now need to do is to setup a Spark Cluster using these machines. To separate the concerns, we will be sticking on to the official Spark Architecture (Documentation) and try to illustrate how the following components are form part of the Architecture.
- Main Components - Hypothesis
- Driver Program :- This should be the user logic and configuration, eh?
- Cluster Manager :- This should be something which manages the Cluster (Hmm, resources and flow ? )
- Worker Node :- This should be something which does the actual work ?
We will try to give a formal definition and the responsibilities of each of these components in a while. Since we are building a Hadoop Spark Cluster, we should
have a Distributed Storage layer built first by connecting all these machines to store the large volumes of data. So in the cluster we are going to build,
we will make the Machine 1 as the Edge Node (A single point of access from where an end-user can perform anything on the cluster) and only 3 out of the 4 remaining
machines(Machine 2, 3 & 4) will only be used to store the data in the cluster and thus form the storage layer (3 * 1 TB = ~3 TB). If you closely observe the different
components in Hadoop Eco-system, almost everything work in a Master-Slave architecture. A master who controls and co-ordinates the actions and the slaves who perform
those actions. In the case of Distributed Storage, the master is called NameNode and the slaves are called DataNodes. So if you try to point them back to our simple
cluster NameNode is a process running on the Machine 5 and DataNodes are individual processes running on Machine 2,3 & 4. Similarly, for managing the task allocation
and resources, the Resource Manager(Master) will be running on Machine 5 and individual Node Managers(slaves) will be running on each of the Machines 2, 3 & 4.
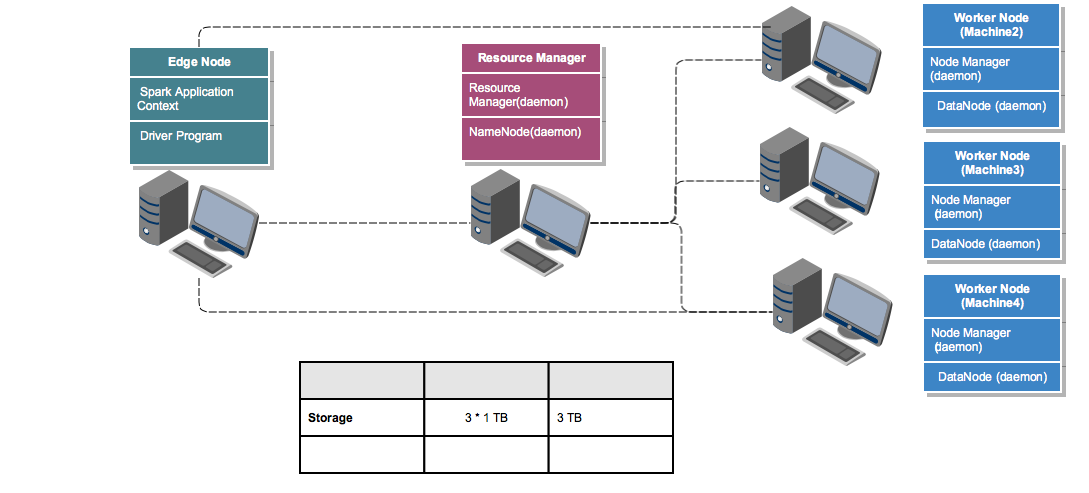
Connecting the Dots - The Capacity of our Cluster!
Now that we have a storage layer to layer to store our ‘Big Data’, there should be some mechanism to do the computation/processing. If we do a quick peek into the Spark Architecture(Yes, I am still following the bottom up method to explain things :D ), we can see Components named Executor with individual Task and Cache. Yes, these are the Heros which gets the work done. We can treat each Executor as individual container with its own Processor and Memory(Virtual Cores - Will be explained in a separate thread - Spark Memory Management - Ideally the V-Cores are equal to the number of physical cores available in each Node). So if we do the math, Each of our Worker Node makes the following contributions to the total capacity of the Cluster.
| * | Attribute | Value | How |
| 1 | Storage | 1 GB | It is the HDD available to Store Data |
| 2 | V - Cores | 5 Cores | Leaving 1 Core for NM, 1 Core for DN and 1 Core for OS |
| 3 | Memory | 10 GB | Leaving 4 GB for OS, NM and DN |
| * | Total | 3 TB HDD + 15 V-Cores + 30 GB | Adding the resources from each of the nodes |
To summarize, the Node Managers will share the Memory and V-Core information to the Resource Managers and the DataNodes will share the Disk space statistics with the NameNodes during their startup. The cumulative information will actually provide the overall capacity of the cluster.
P.S: There are more to this like pluggable Capacity Scheduler and the Algorithm for Calculating the resource availability (Default Resource Calculator and DominantResource Calculator using Dominant Resource Fairness ) - We will talk about this in a separate thread Resource Scheduling
The continuation of this discussion will happen in the next Post Spark Architecture : Part 2 - Let’s set the ball rolling