The Summum Bonum!
-
A Humble attempt to Understand Streaming Data and the way we process it!
- Batch Data Vs Streaming Data …
- Indefinite flow of data …
- #Process_Pattern_1 : Process data as and when it is available.
Recently my friend has asked me, “Dude, it’s been quite some time that you have been working on Big Data and related software stacks. I have a simple problem and could you please educate me on these jargons and provide a suitable solution ? “
The inherent repulsive behaviour in me have put me in a defensive mode but I somehow mustered enough courage to hear the problem statement out and it goes like this :-
"Let's assume that you have a stream of data flowing in and I want to put the data into different buckets by aligning with the following rules :- 1. The records in a given bucket shouldn't be duplicates 2. All the incoming data should be emitted out i.e the collection of data in different buckets will be the same as incoming data. Once, the data is arranged in different buckets, we should be able to call a Sink. Let's assume this as an HTTP API Service / HDFS output location.Whenever I am encountered with a problem, I will try to picturise the statement in my mind (I assume our brain has some ‘magical’ power to process and give out results when we lift problem statements into diagrams with box and connectors :) ) and that goes like this :-
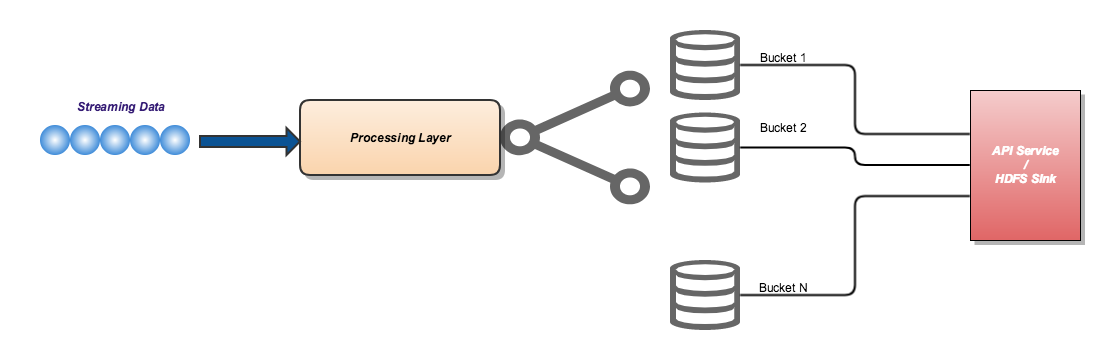
Ok, we are successful in plotting the problem statements using box and connectors. But, I already find myself bombarded with lot of questions which I am not certain about.
- What is a streaming data ?
- What is the best mechanism to ingest it.
- Even if I find a mechanism to ingest the data how much of the incoming data will can be processed at a time ?
- What all things can be done with the streaming dataset and methods available for sink ?
We will try to answer each of these questions at different points in the journey.
As we all do, my immediate reflex was to google on these jargons and without much hassle I was able to come up with the following conclusions.
Batch Data Vs Streaming Data …
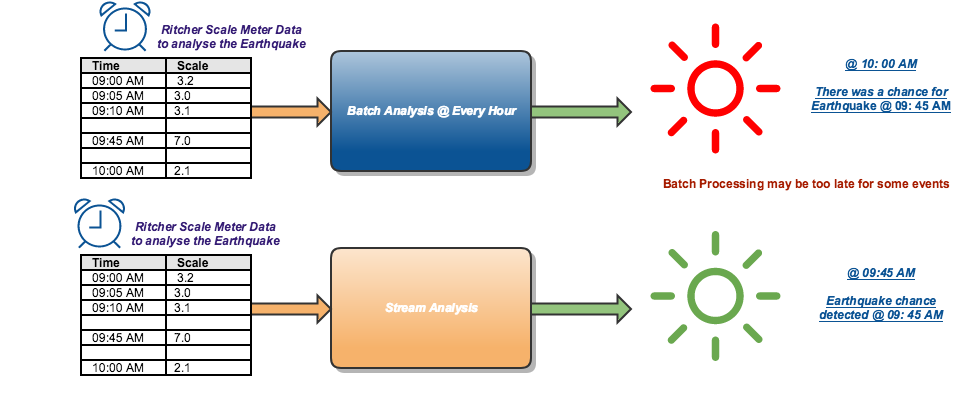
In real world data is generated majorly in two ways, end result of a statistical analysis or by the end result of an event. Lets say, if I am periodically checking the account balances of customers in a bank or memory usage in a computer and records it as a dataset then it can be fairly be categorised as dataset derived out of statistical analysis. There is another class of dataset generated out of instances like data generated by sensors, security systems, medical devices based on events happening at their habitat. We couldn’t simply predict the occurrence interval of those data. For instance, lets treat the webserver logs as a dataset and the data will be continuously generated whenever someone accesses any of the websites hosted on that server. This continuous flow of events can be called as streaming dataset. In a typical Big Data Environment, the need for performing real-time stream processing is rapidly increasing and below is some witty but striking example to reason the statement.
Indefinite flow of data …
Now that we know the difference between the Batch Data and Streaming data processing, the very first concern that would come to our mind is its behaviour - the indefinite flow of incoming data. We should have a mechanism to make sure that all the incoming data is processed as and when it is available. In layman terms, I can think of couple of ways to handle this scenario
- Have a processing layer capable of processing the data as and when it is available. - #Process_Pattern_1
- Have a queueing system in place to hold the incoming data and let the processing layer source the data from there and process. #Process_Pattern_2
On further research, I narrowed down my options for the Processing Layer. We can either use Spark Streaming / Storm as a processing layer and and Kafka / Flume as queuing system to control the flow of incoming data before it is served for processing.

But, in this post we will be concentrating only on the Spark Streaming + Kafka Integration to implement the solution to the problem we had started with.
#Process_Pattern_1 : Process data as and when it is available.
Before coming into a solution, we will try to get a basic understanding about the Processing Layer (Spark Streaming) using a simple network word count application. Let’s assume that we have a netcat server as a source for streaming dataset and our aim is to compute the word count on the incoming data. In the case of batch mode word count, Simple Word Count using Spark, we were reading in the source dataset, doing the RDD transformations and computes the word count on the whole dataset and finally the results were written on to the disk. In that case the actual computation was done on the whole dataset. But, when it comes to the real time streaming, we do not know what can be the size of the dataset and when should the computation on that defined dataset be emitted out. This is where the relevance of a ‘streaming-batch’(think about separation of concerns :) ) comes into picture.
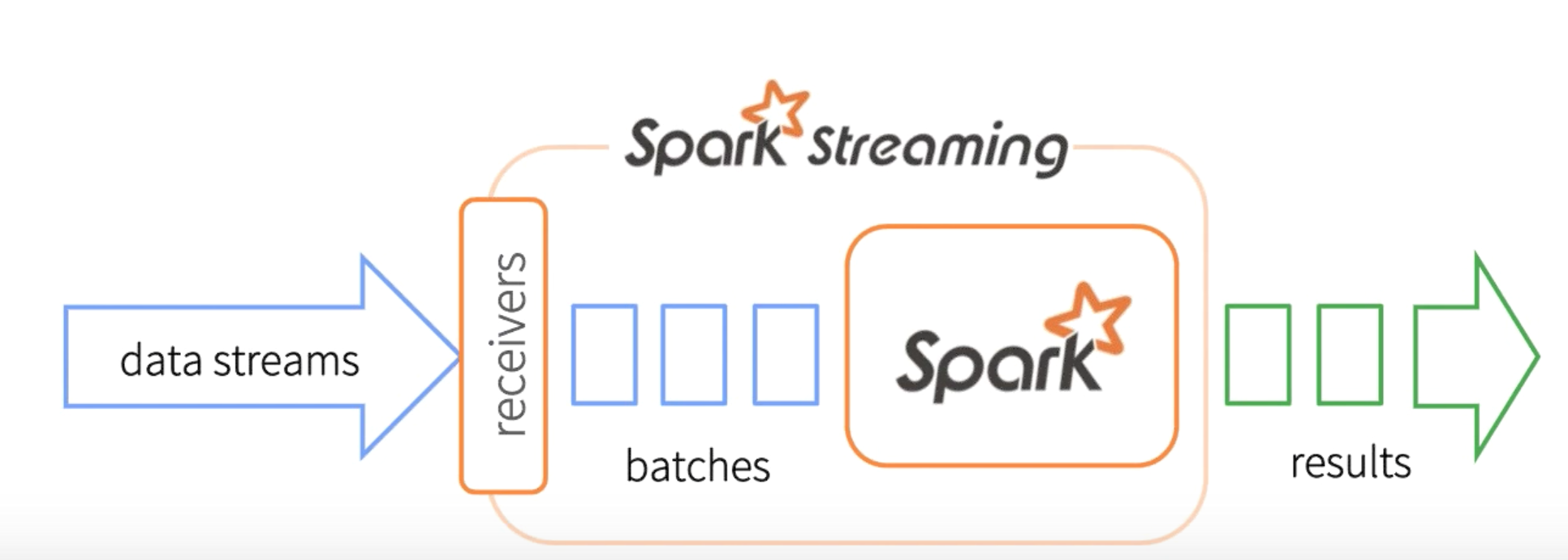
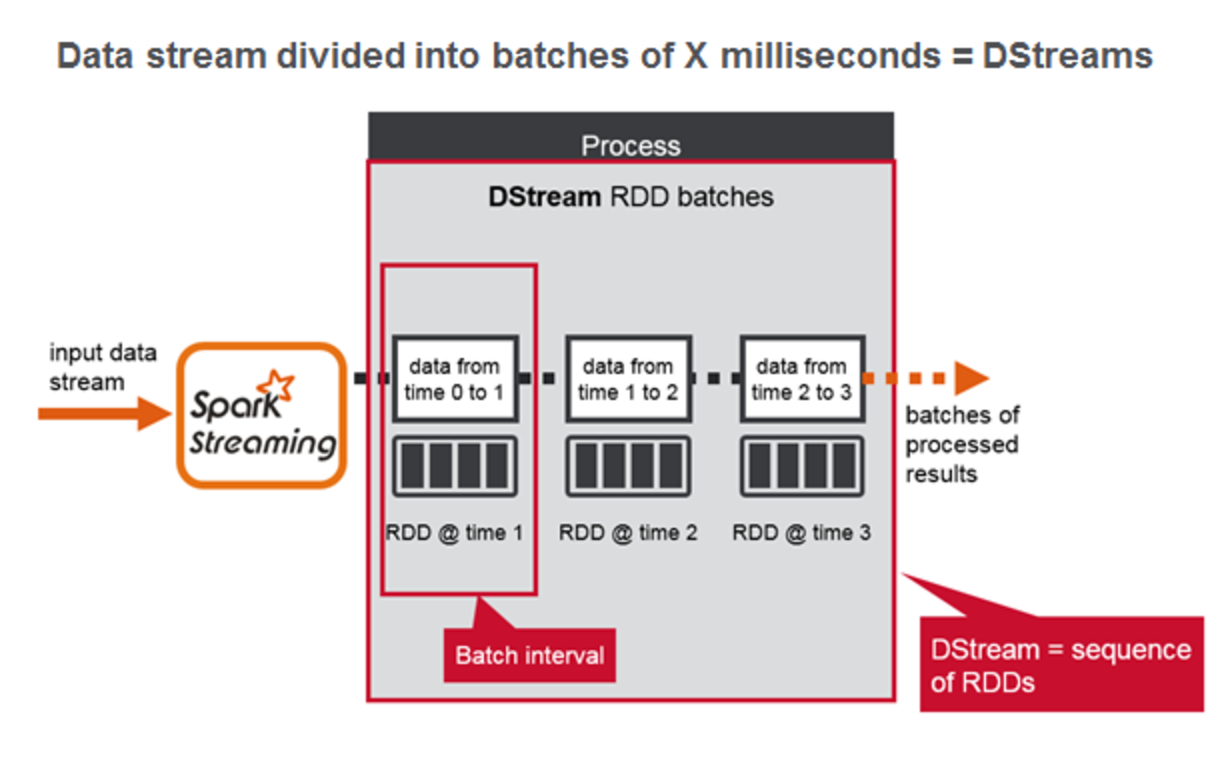
Yes, you guessed it right. In a streaming context it is not the amount of data that defines a batch but rather it’s the time duration that defines it. If you split the timeline into intervals of say 1s, 2s or 3s etc then we can very well define a batch as the totality of data that came over that period of time. But the Spark Streaming optimizes the streaming batches by introducing one more concept called DStreams. Spark Streaming divides the data stream into batches of X seconds called Dstreams(Discretized Streams), which internally is a sequence of RDDs, one for each batch interval. Each RDD contains the records received during the batch interval.
Before going further into any more discussion, we will switch our context back to the WordCount Program (Yep, Bottom Down approach). Suppose we have a streaming data source(netcat, for the time being) and we want to perform the word count on the streaming dataset. The implementation is given below for reference.
// Create the context with a 1 second batch size val sparkConf = new SparkConf().setMaster(args(0)).setAppName("NetworkWordCount") val ssc = new StreamingContext(sparkConf, Seconds(1)) // Create a socket stream(ReceiverInputDStream) on target ip:port val lines = ssc.socketTextStream(args(1), args(2).toInt, StorageLevel.MEMORY_ONLY) // Split words by space to form DStream[String] val words = lines.flatMap(_.split(" ")) // count the words to form DStream[(String, Int)] val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _) // print the word count in the batch wordCounts.print() ssc.start() ssc.awaitTermination()Internally, it works as follows. Spark Streaming receives live input data streams and divides the data into batches, then the sequence of RDDS(DStreams) will then be processed by the Spark engine to generate the final stream of results. There are two types of operations on DStreams i.e transformations and output operations. Every Spark Streaming application processes the DStream RDDs using Spark transformations which create new RDDs. Any operation applied on a DStream translates to operations on the underlying RDDs, which in turn, applies the transformation to the elements of the RDD. Output operations, like saving the HDFS or calling an external API will produce output in batches.
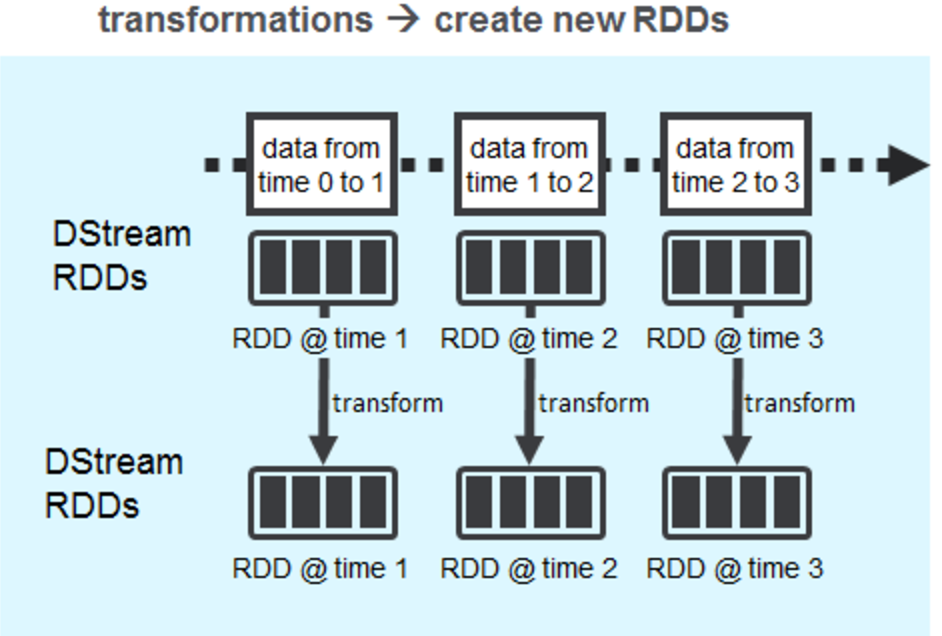
Yes, the opportunist in you have guessed it right, once we have a sequence of RDDS - you are empowered and transcended to a a world where you are free to do anything which you can perform on an RDD - be it MLlib, Graph and you name it - Awesomeness!
Something is worrying You!
Yes, from the top of my head, I could sense a lot of questions cooking up.
- Will I be able to process all the data which streams in ?
- what all things have been considered for the fault-tolerance while processing this fast paced data ingest
- Who will be responsible for receiving the data etc.
Ok, since everything ultimately boiling down to RDD processing, we very well know that the processing will ultimately happen in Spark Driver Program and Executors.
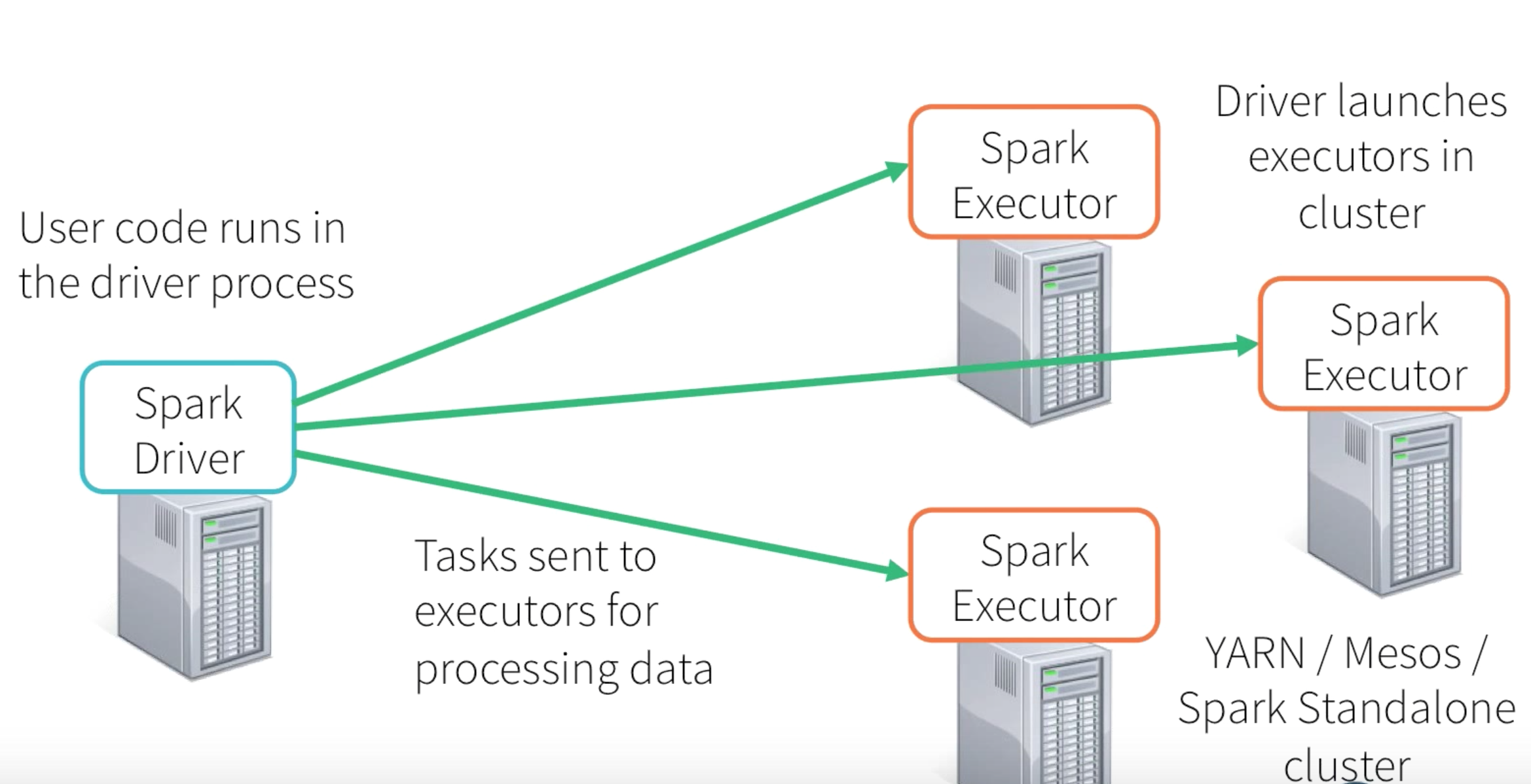
Let’s try to solve the questions in the chronological order of relevance and see whether we can come up with some answers. In that case the very first question would be how will be responsible for receiving the data.
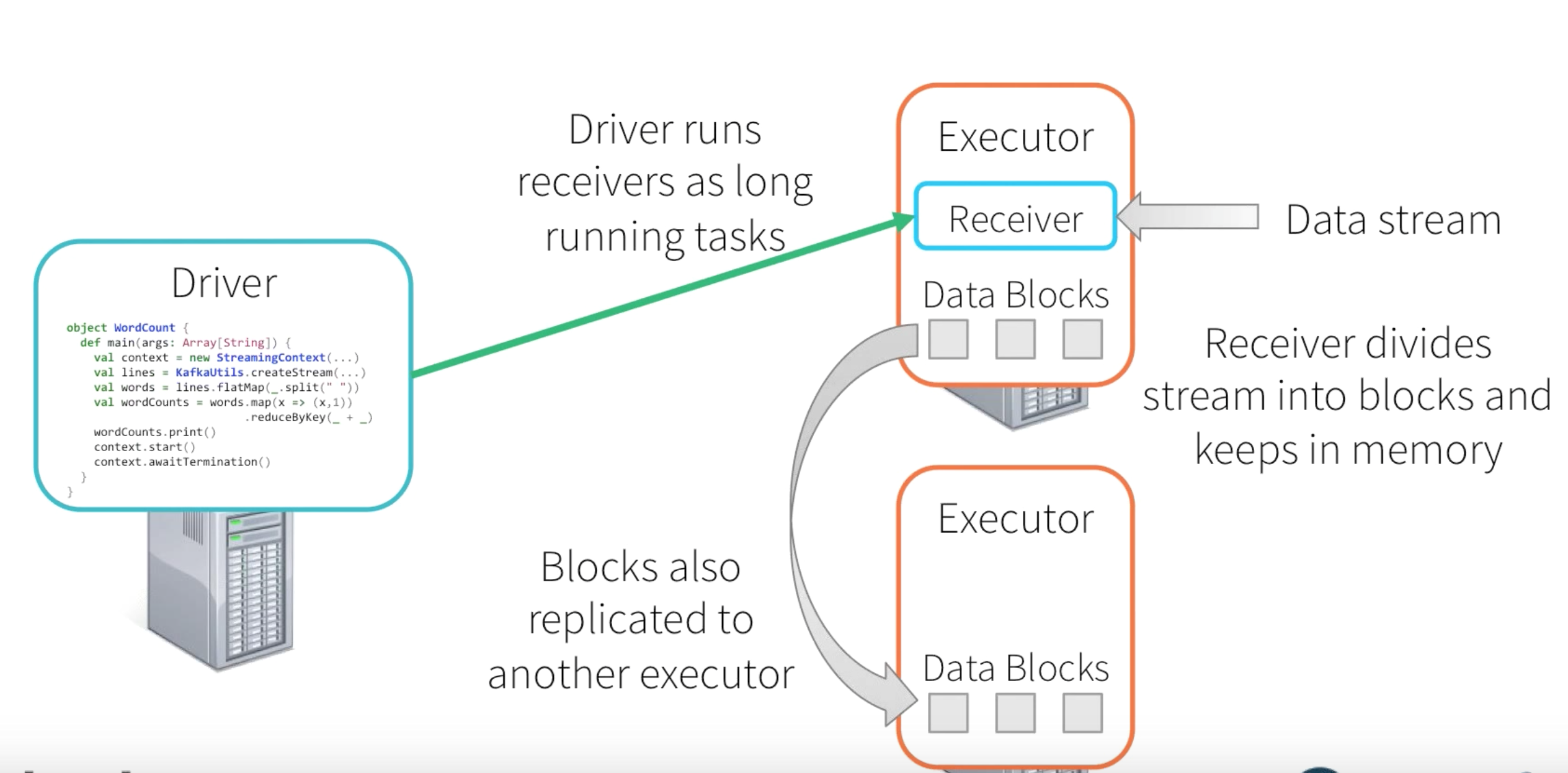
Depending upon the type of input streaming data source, the corresponding DStream is associated with a Receiver object which receives the data from a source and stores it in Spark’s memory for processing. Spark Streaming provides two categories of built-in streaming sources.
- Basic sources: Sources directly available in the StreamingContext API. Examples: file systems, and socket connections.
- Advanced sources: Sources like Kafka, Flume, Kinesis, etc. are available through extra utility classes.
In the current Context(Network Word Count), we are using the ReceiverInputDStream for the Socket Stream Source. The Receivers are long running process in one of the Executors and its life span will be as long as the driver program is alive. The Receiver receives data from socket connection and separates them into blocks. This generated block of data will be replicated among different executor memory. On every batch interval the Driver will launch tasks to process the blocks of data and the subsequent results will be sinked to the destination location.
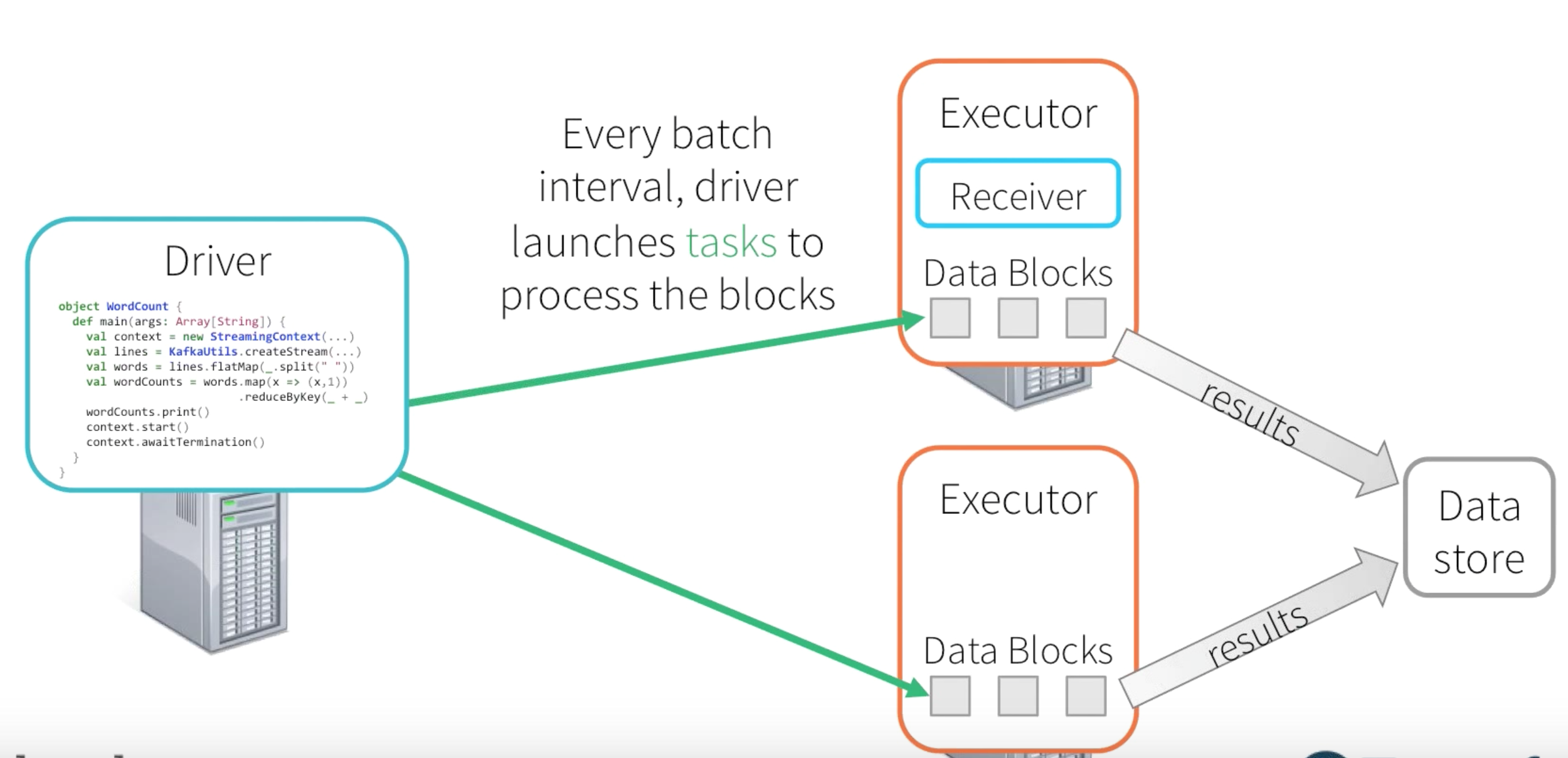
Okay, now that we have the answer for the question on who will be responsible from receiving the streaming data, the next intriguing question would be on the fault-tolerance. We know that everything is now boiled down to Spark native habitat the possible faulty prone scenarios that can occur would be : -
-
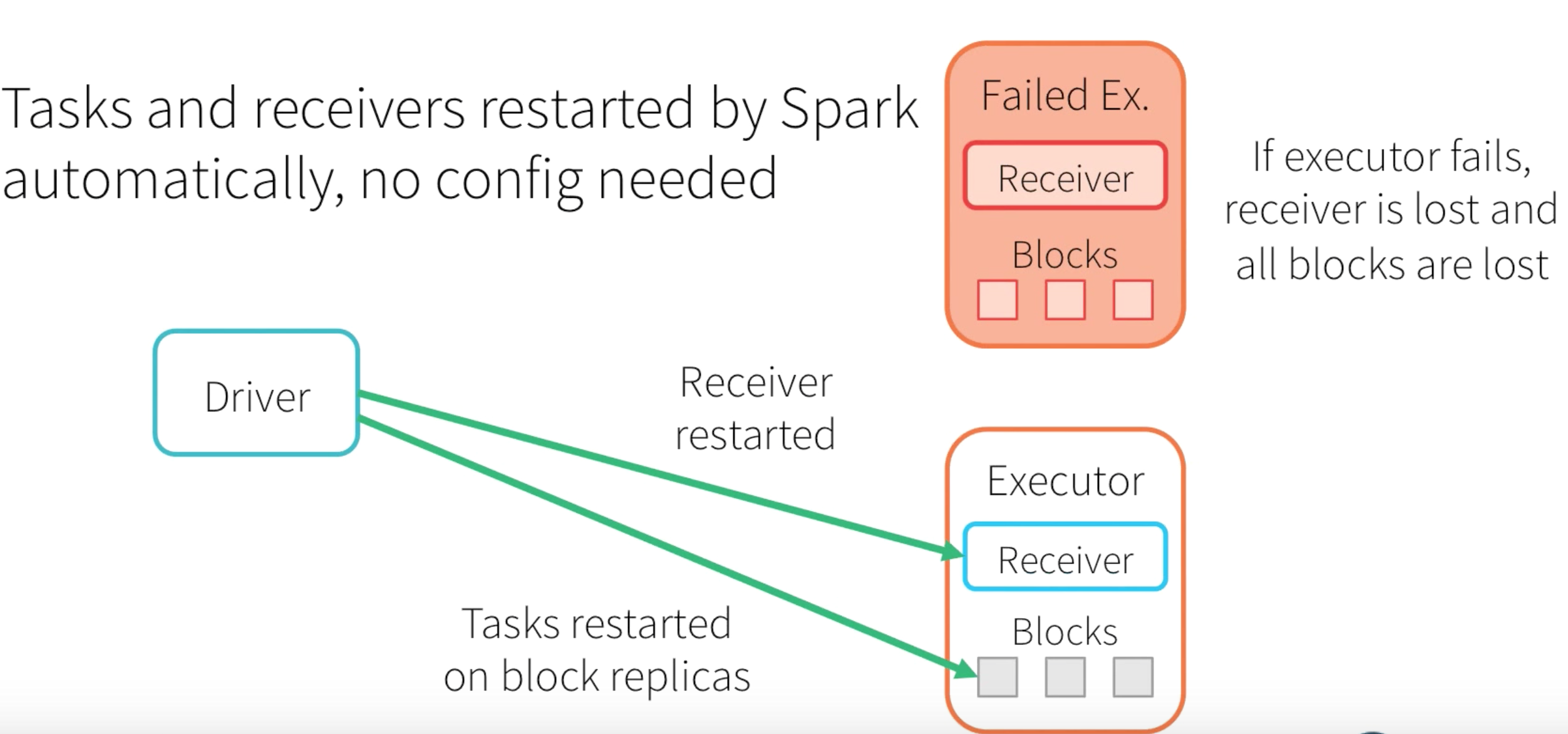
What if the Executor Fails : -
If the Executor is failed then the Receiver and the stored memory blocks will be lost and then the Driver will trigger a new receiver and the tasks will be resumed using the replicated memory blocks.
-
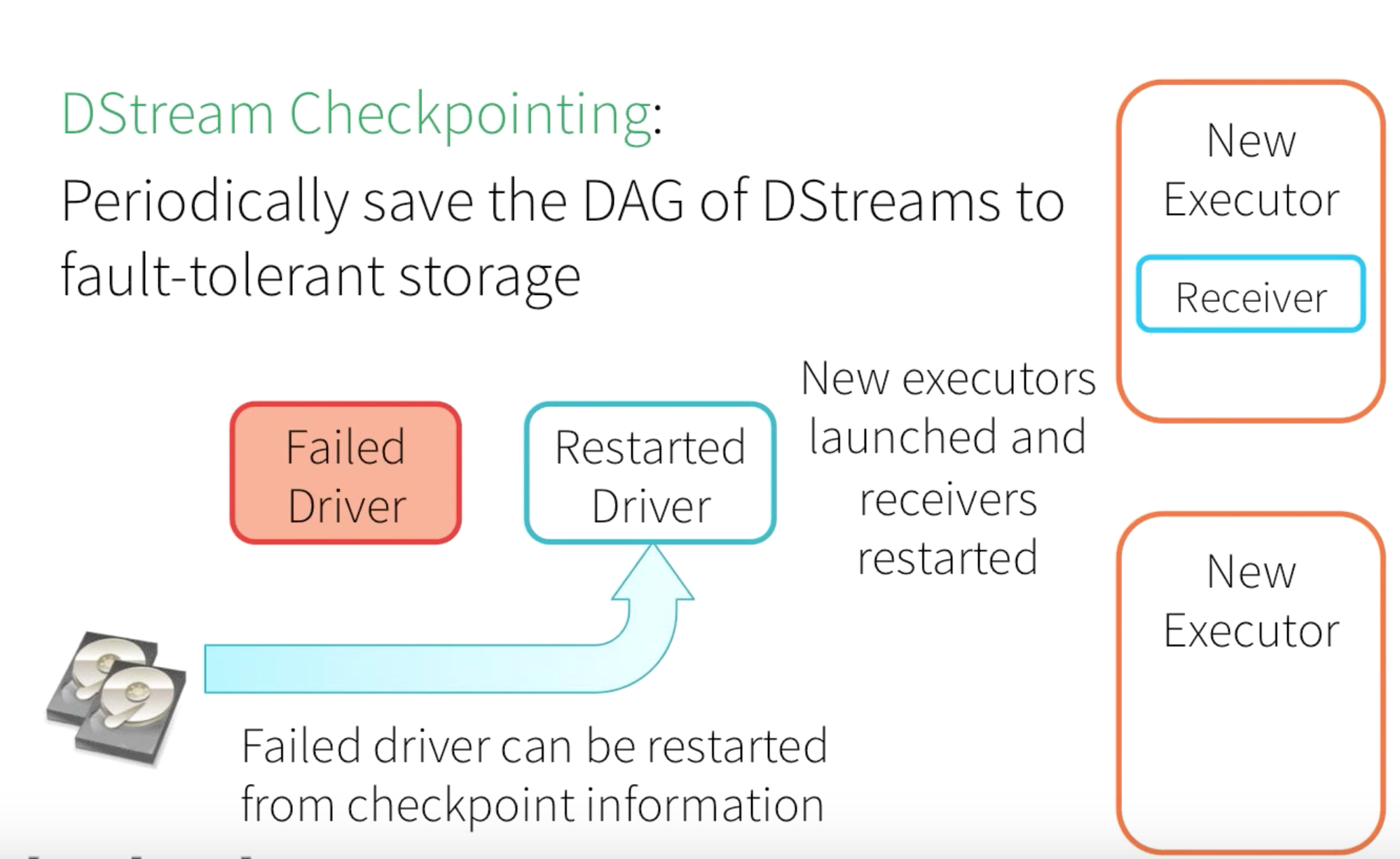
What if the Driver Program Fails : -
When the Driver Program is failed, then the corresponding Executors as well as the computations, and all the stored memory blocks will be lost. In order to recover from that, Spark provides a feature called DStream Checkpointing. This will enable a periodic storage of DAG of DStreams to fault tolerant storage(HDFS). So when the Driver, Receiver and Executors are restarted, the Active Driver program can make use of this persisted Checkpoint state to resume the processing.
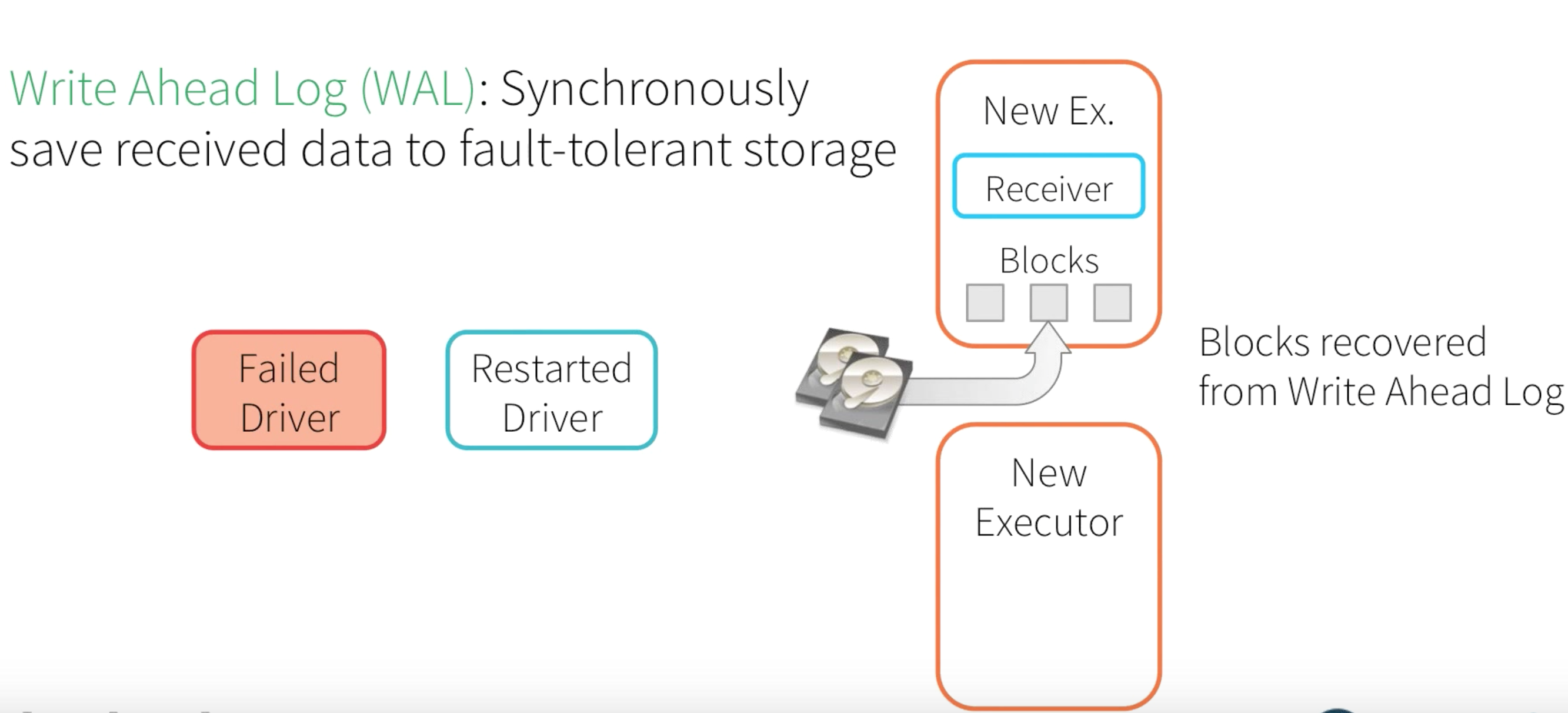
Even if we are able to restart the Checkpoint state and start processing from the previous state with the new Active Executor, Driver program, and Receiver - we need to have a mechanism to recover the memory blocks at that state. In order to achieve this, Spark comes with a feature called Write Ahead Log (WAL) - This will synchronously saves memory blocks into fault-tolerant storage.
To enable the whole fault-tolerance, we should perform the following changes to our Network WordCount Program : -
- Enable Checkpointing
- Enable WAL in SparkConf
- Disable in-memory Replication
- Receiver should be reliable : Acknowledge Source only after data is saved to WAL. Untracked data will be replayed from source.
If you apply the above fault-tolerance changes then the whole NetworkWordCount program will look something like this : -
def main(args: Array[String]) { if (args.length < 3) { System.err.println("Usage: NetworkWordCount <master> <hostname> <port> <duration> <checkpoint directory>") System.exit(1) } StreamingExamples.setStreamingLogLevels() val ssc = StreamingContext.getOrCreate(args(4), () => createContext(args)) ssc.start() ssc.awaitTermination() } def createContext(args: Array[String]) = { // Create the context with a 1 second batch size val sparkConf = new SparkConf().setMaster(args(0)).setAppName("NetworkWordCount") sparkConf.set("spark.streaming.receiver.writeAheadLog.enable", "true") val ssc = new StreamingContext(sparkConf, Seconds(args(3).toInt)) // Create a socket stream(ReceiverInputDStream) on target ip:port val lines = ssc.socketTextStream(args(1), args(2).toInt, StorageLevel.MEMORY_AND_DISK_SER) // Split words by space to form DStream[String] val words = lines.flatMap(_.split(" ")) // count the words to form DStream[(String, Int)] val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _) wordCounts.print() ssc.checkpoint(args(4)) ssc }Have you noticed something fishy in the existing implementation - Hmm, A reliable friend - Yes, a reliable source who can acknowledge our hope, well-being and happiness :).
We will talk about that in the sequel… To Be Continued! :)
-
Implicits and Type Classes
Implicits and Type Classes
-
CCA 175 - Cloudera Spark & Hadoop Certification - Part 1
Part 1 - The Road Map
-
Should be able to import Tables from MySQL Databases. Code Snippets : https://github.com/dgadiraju/code/tree/master/hadoop/edw/cloudera/sqoop Itversity YouTube Channel
https://www.cloudera.com/developers/get-started-with-hadoop-tutorial/exercise-1.html
Boundary Query
Useful Links
-
-
Spark Architecture : Part 2 - Let's set the ball rolling
Please note that this is a continuation from Spark Architecture : Part 1 - Making sure that the basement is right!
Baby Step 1 : Prepare your executable
Now that we have the cluster (with HDFS Layer, Node Manger and Resource Manager) in place we will name this state as ‘Dot1’. Keeping this aside, now we will switch our context back to the WordCount Program we have already written and tested WordCount - Spark Our aim is to run this WordCount Program in Spark Cluster and see how it interacts with different components and dissect each components to see what exactly is happening under the hood to define rest of the components in the Architecture.
// RDD 1 val inputRDD = sc.textFile(inputPath) // RDD2 val wordsRDD = inputRDD.flatMap(_.split("\\s+")) // split words // RDD 3 val tuplesRDD = wordsRDD.map(w => (w, 1)) // RDD 4 val reducedRDD = tuplesRDD.reduceByKey(_ + _) // Action reducedRDD.saveAsTextFile(outputPath)So the core of the WordCount Program is shown above and we are ready with the executable. In the cluster, we have already identified a physical machine as the Edge Node(Assume that we have already installed the Spark Cluster and all the Spark Binaries are available in the Edge Node). When we submit the Job, the execution flows through the following steps.
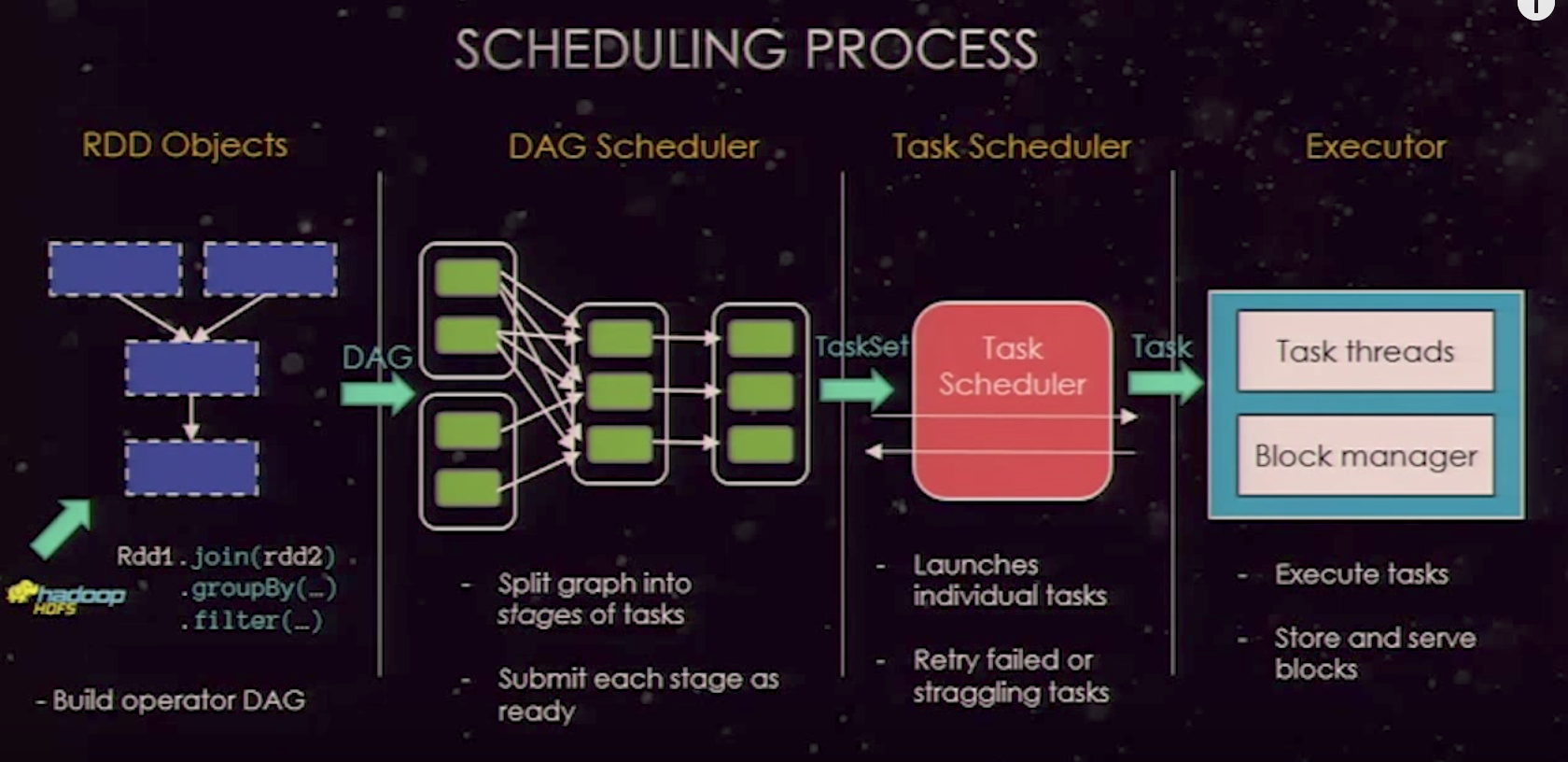
- Spark Will identify what is the List of RDDs in the program and the lineage between them. When any action(Actions & Transformation) is called on the RDD, spark creates the DAG(Directed Ascylic Graph) and sends it to the DAG Scheduler.
-
The DAG Scheduler splits the operations into different stages. As we already discussed there are mainly two types of operations that result in RDD - i.e Transformations and action among this there can be two types of Transformations one is narrow transformation and the other one is wide transformation(involves shuffling - i.e network transfer). The wide transformation determines the stage boundaries(i.e it is a trigger for next stage; Eg: reduceByKey, groupBy etc). So our WordCount program, RDD4 defines the boundary and all the operations in RDD1, RDD2 and RDD3 can go in single stage and the operations can be coupled together and parallelised. RDD4, RDD5 groups together to form the Stage 2.
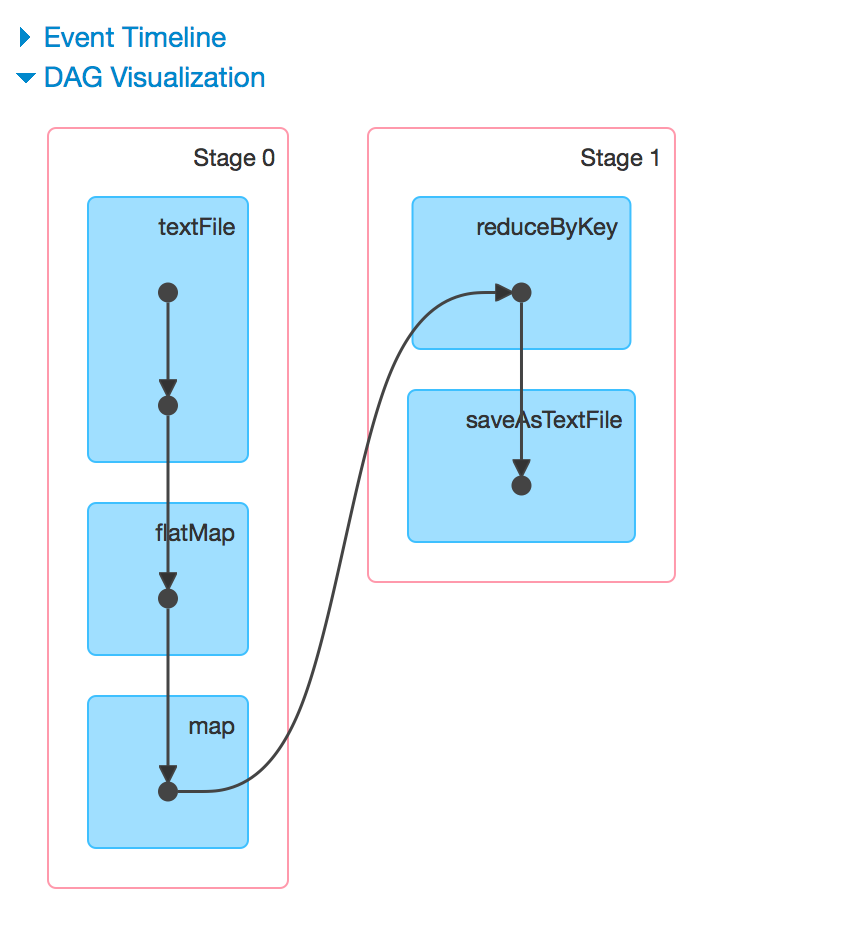
-
Once the DAG is generated, each stages will be send as an input to the Task Scheduler to generate the physical execution plan. The number of physical tasks spawned depends on the number of partitions generated out of the file (Based on Block size). For instance, in our case say if we are processing 1.5 GB data then the number of tasks spawned will be 1.5 GB / 128 MB = 12. Now the question is how these tasks are shared to get the work done. That is where the Worker Node comes into the picture. Ok, now that I have 12 tasks to process and assume that spark(by default) spawned two Executors to to get the work done. Let’s assume that the 2 executors spawned are having the configuration of 512 MB (Container Memory) and 1 V-Core and we have 12 Tasks to complete. It is very obvious that the all of the 12 tasks can be processed at once because the core will only function in a time sharing manner and at most 2 tasks can be executed in parallel. So task1 will be allotted to the Executor of the node 1 (Depends on the data locality) and the task 2 will be allotted to the next. Depending up on whoever completes the task first will get the subsequent task allocated and once all the 12 Tasks are done in this fashion, the Stage 1 will be completed.
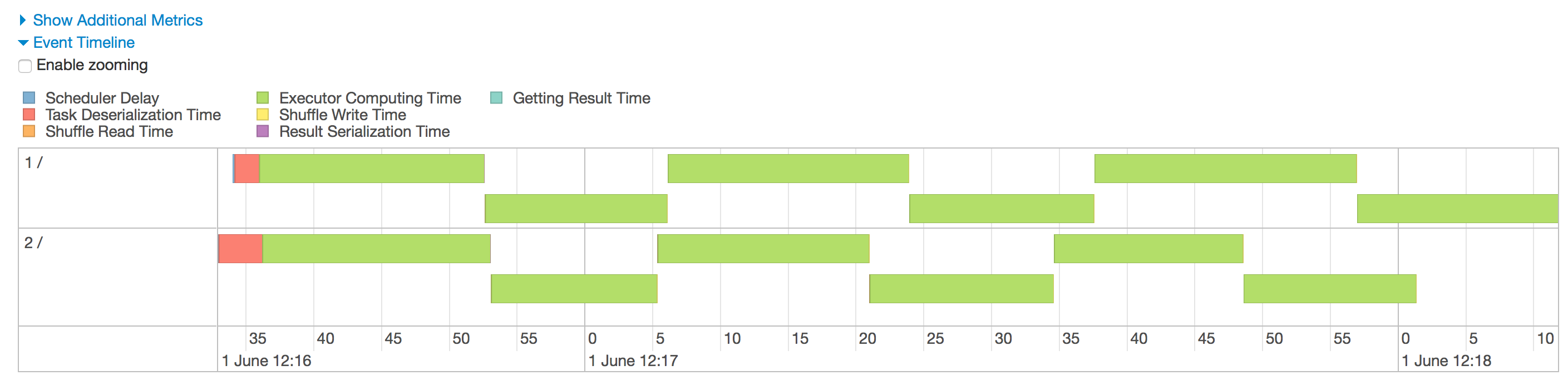
The Stage 2 (Starts with the shuffled dataset) will always have the same number of tasks as that of the stage 1(unless and otherwise if you repartition the RDD)
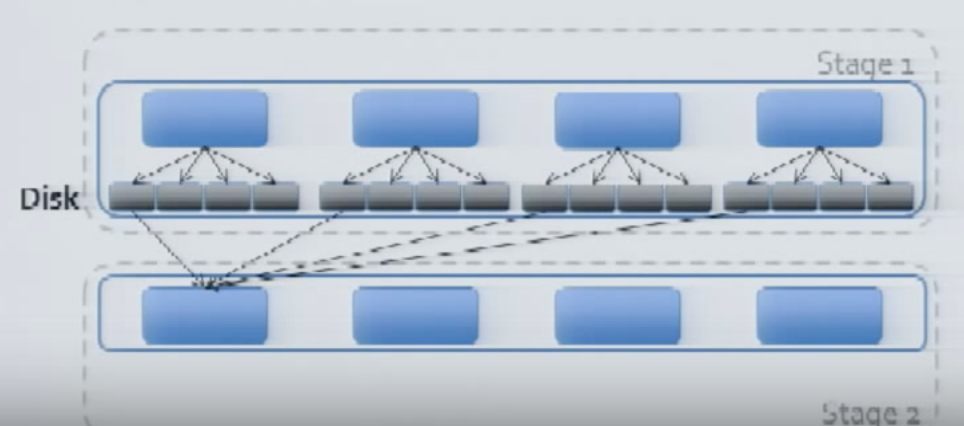
The tasks of the Stage 2 will also get executed based on the Executor/Core availability and the final data will be written on to the target file.
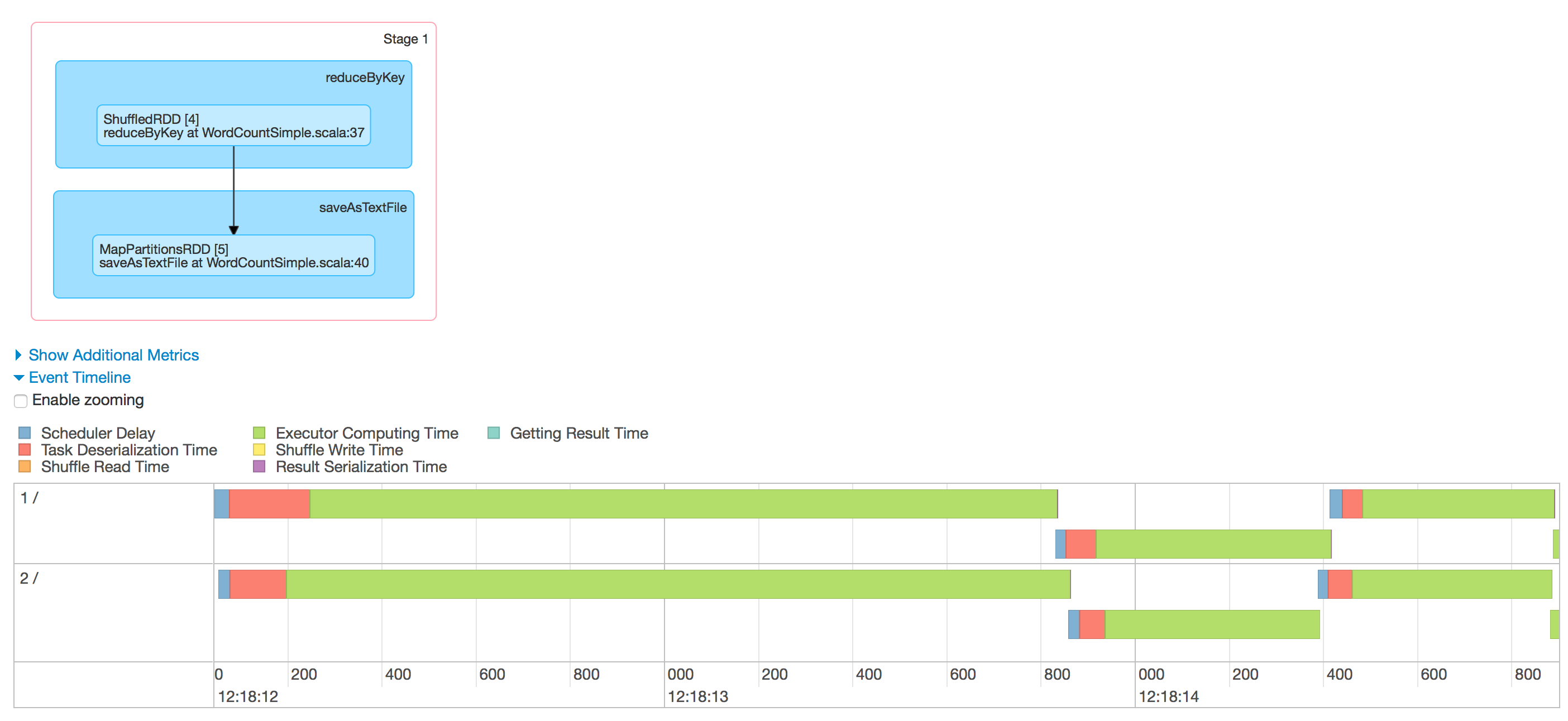
One interesting thing to notice over here is that the Mapper and Reducer Phases ran on the Same Node and they are re-using the Executor JVM for the processing and this is one of the main reason why Spark is so Powerful (Yes, the Caching Mechanism to store the data in RAM is also there). There are more things coming up on the Memory Management and Executor Memory Turning on Part 3 - One More Baby Step : Executor Memory Management and Tuning
-
Spark Architecture : Part 1 - Making sure that the basement is right!
- The basics (Quick glance through what we already know)
- Connecting the Dots
- Connecting the Dots - The Capacity of our Cluster!
When I wanted to learn about Spark and its Architecture, to get it from horses mouth, I went directly to the Apache Spark homepage Spark Architecture. Not surprisingly, I was presented with a neat Architecture diagram and a collection of jargons to start with - Cluster manager, Driver Program, Spark Context, Worker node, Executor, Task, Job, Stage.
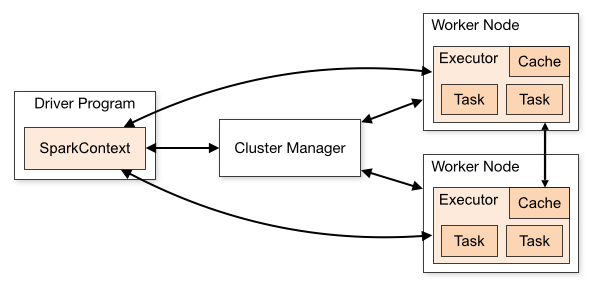
Since I have been working with Big Data Technologies for quite some time, I was able to map the things on a high level. Not recently, I started imbibing a pattern of learning in which I mark something as learned if and only if I am successful in making another person understand that concept in the most simple terms. So sticking on to that thumb rule and to force the zen pattern, I am trying to to explain the Architecture from a different(more practical) point of view(I presume you have basic understanding of Hadoop and MapReduce).
The basics (Quick glance through what we already know)
We all know that the Spark Architecture sits on top of the Hadoop Platform. So, the simple layman question - What is a Hadoop cluster and why do we need it ?
As per Wiki - Apache Hadoop is an open-source software framework used for distributed storage and processing of dataset of big data using the MapReduce programming model.To understand the need and evolution of Hadoop-MapReduce, I suggest you to go through the below write up :-
Evolution of Hadoop and MapReduce
P.S : - More to Come on this introduction part.
Connecting the Dots
Ok, Let’s try to see the whole architecture from a different perspective. We all know that the Hadoop cluster is “made” using the commodity Hardwares and let’s assume that we have 5 Physical machines each of them is having a basic configuration (16GB RAM, 1 TB HDD, and 8 Core Processors).

Ta-da, we have got the physical machines in place and we now need to do is to setup a Spark Cluster using these machines. To separate the concerns, we will be sticking on to the official Spark Architecture (Documentation) and try to illustrate how the following components are form part of the Architecture.
- Main Components - Hypothesis
- Driver Program :- This should be the user logic and configuration, eh?
- Cluster Manager :- This should be something which manages the Cluster (Hmm, resources and flow ? )
- Worker Node :- This should be something which does the actual work ?
We will try to give a formal definition and the responsibilities of each of these components in a while. Since we are building a Hadoop Spark Cluster, we should have a Distributed Storage layer built first by connecting all these machines to store the large volumes of data. So in the cluster we are going to build, we will make the Machine 1 as the Edge Node (A single point of access from where an end-user can perform anything on the cluster) and only 3 out of the 4 remaining machines(Machine 2, 3 & 4) will only be used to store the data in the cluster and thus form the storage layer (3 * 1 TB = ~3 TB). If you closely observe the different
components in Hadoop Eco-system, almost everything work in a Master-Slave architecture. A master who controls and co-ordinates the actions and the slaves who perform those actions. In the case of Distributed Storage, the master is called NameNode and the slaves are called DataNodes. So if you try to point them back to our simple cluster NameNode is a process running on the Machine 5 and DataNodes are individual processes running on Machine 2,3 & 4. Similarly, for managing the task allocation and resources, the Resource Manager(Master) will be running on Machine 5 and individual Node Managers(slaves) will be running on each of the Machines 2, 3 & 4.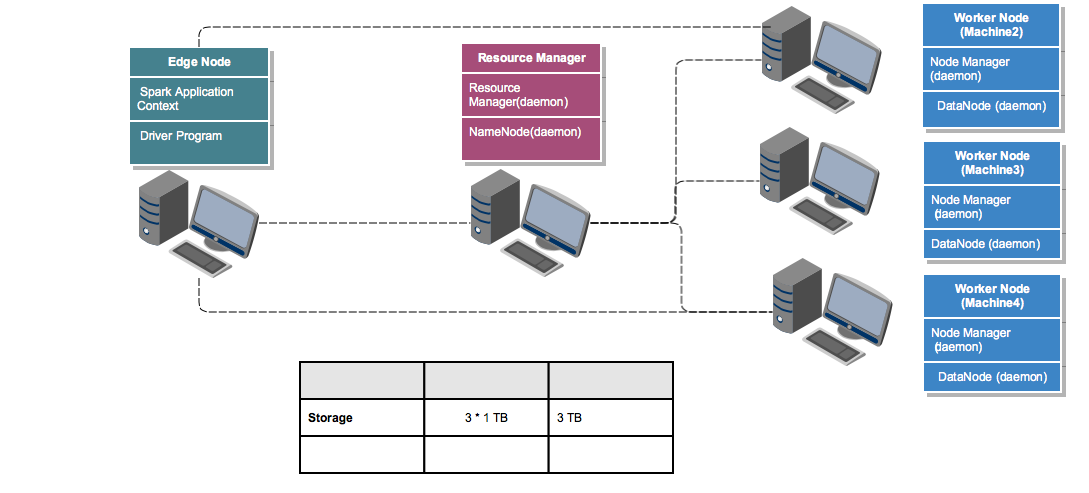
Connecting the Dots - The Capacity of our Cluster!
Now that we have a storage layer to layer to store our ‘Big Data’, there should be some mechanism to do the computation/processing. If we do a quick peek into the Spark Architecture(Yes, I am still following the bottom up method to explain things :D ), we can see Components named Executor with individual Task and Cache. Yes, these are the Heros which gets the work done. We can treat each Executor as individual container with its own Processor and Memory(Virtual Cores - Will be explained in a separate thread - Spark Memory Management - Ideally the V-Cores are equal to the number of physical cores available in each Node). So if we do the math, Each of our Worker Node makes the following contributions to the total capacity of the Cluster.
* Attribute Value How 1 Storage 1 GB It is the HDD available to Store Data 2 V - Cores 5 Cores Leaving 1 Core for NM, 1 Core for DN and 1 Core for OS 3 Memory 10 GB Leaving 4 GB for OS, NM and DN * Total 3 TB HDD + 15 V-Cores + 30 GB Adding the resources from each of the nodes To summarize, the Node Managers will share the Memory and V-Core information to the Resource Managers and the DataNodes will share the Disk space statistics with the NameNodes during their startup. The cumulative information will actually provide the overall capacity of the cluster.
P.S: There are more to this like pluggable Capacity Scheduler and the Algorithm for Calculating the resource availability (Default Resource Calculator and DominantResource Calculator using Dominant Resource Fairness ) - We will talk about this in a separate thread Resource Scheduling
The continuation of this discussion will happen in the next Post Spark Architecture : Part 2 - Let’s set the ball rolling
-
Monad Explained! - The Scala way
Monad
P.S: Just Rough Notes - WIP - Will have to Develop to a readable content :)
Monad, M[T], is an amplification (or considered as a wrapper) of a generic type T such that
-
Any Monad, M[T] can be created by applying a creation function on T x: T => M[T]
-
It provides a mechanism to for applying a function which takes T and gives out Monad of the resultant type
(x: M[T], fn: T => M[Z]) => M[Z]
These two featurs must obey the following 3 Monadic law : -
-
If you apply the Monad creation function to an any existing Monadic instnace then it should give out a logical equivalent Monad
monad1 = M[T] monad2 = creationFn(monad1)
monad 1 and monad2 should be same
-
Appying a function to the result of applying the construction function should always produce a logically equivalent Monad if we apply that function directly on the value
-
Composition rule :
val f = (X) => M[Y] val g = (Y) => M[Z] M[X] mx = f; val my : M[Y] = monadicFunction(mx, f) val mz1 : M[Z] = monadicFunction(my, g) val h: M[Z] = monadicCompose(f, g); val mz2 = monadicFunction(mx, h);Applying to a value a first function followed by applying to the result a second function should produce a logically identical Monad if you applying a composition function to the origial value.
-
- A Humble attempt to Understand Streaming Data and the way we process it!
- Implicits and Type Classes
- CCA 175 - Cloudera Spark & Hadoop Certification - Part 1
- Spark Architecture : Part 2 - Let's set the ball rolling
- Spark Architecture : Part 1 - Making sure that the basement is right!
- Monad Explained! - The Scala way
- A reborn child!